介绍
本指南的目的是为对制作高质量压制感兴趣的新人提供一个起点,同时也为有经验的压制人员提供参考。 因此,在介绍了大多数功能和解释了它们的用途之后,可以找到一个深入的解释。 这些都是为好奇者提供的简单补充,不是使用相关方法的必要阅读。
译者前言
该指南原始档案: mdbook-guide
指南主要贡献者Aicha,知名压制组组员,贡献很多高质量压制作品。
指南内容丰富,结合作者的自身经验深入浅出讲解压制技巧与流程,虽然部分章节仍未完成,但不可否认这仍是一份难得的压制指南。
翻译此指南旨在分享,希望可以帮助他人,了解,学习高质量压制,压制出优秀的作品。部分名词翻译不到位,还请谅解。
术语
为此,涉及有关视频的基本术语和知识。 一些解释将被大大简化,因为在 Wikipedia、AviSynth wiki 等网站上应该有很多页面对这些主题进行解释。
视频
消费类视频产品通常存储在 YCbCr 中,该术语通常与 YUV 互换使用。在本指南中,我们将主要使用术语 YUV,因为 VapourSynth 格式编写也是 YUV。
YUV 格式的内容将信息分为三个平面: Y, 指代 luma, 表示亮度, U 和 V,分别表示色度平面。 这些色度平面代表颜色之间的偏移,其中平面的中间值是中性点。
这个色度信息通常是二次采样的, 这意味着它存储在比亮度平面更低的帧大小中。 几乎所有消费者视频都采用 4:2:0 格式,这意味着色度平面是亮度平面大小的一半。 关于色度子采样的Wikipedia 应该足以解释这是如何工作的。 由于我们通常希望保持 4:2:0 格式,因此我们的框架尺寸受到限制,因为亮度平面的大小必须被 2 整除。 这意味着我们不能进行不均匀的裁剪或将大小调整为不均匀的分辨率。 但是,在必要时,我们可以在每个平面中单独处理,这些将会在 过滤章节 进行解释。
此外,我们的信息必须以特定的精度存储。 通常,我们处理每平面 8-bit 的精度。 但是,对于UHD蓝光来说,每平面标准是 10-bit 的精度。 这意味着每个平面的可能值范围从 0 到 \(2^8 - 1 = 255\)。 在 位深章节, 我们将介绍在更高的位深精度下工作,以提高过滤过程中的精度
VapourSynth
我们将通过 Python 使用 VapourSynth 框架来进行裁剪、移除不需要的黑色边框、调整大小和消除源中不需要的产物。 虽然使用Python听起来令人生畏,但没有经验的人也不必担心,因为我们只做非常基本的事情。
关于 VapourSynth 配置的资料不计其数,例如 the Irrational Encoding Wizardry's guide 和 VapourSynth documentation。 因此,本指南不会涵盖安装和配置。
在开始编写脚本前,知道每个clip/filter都必须有一个变量名是非常重要的:
clip_a = source(a)
clip_b = source(b)
filter_a = filter(clip_a)
filter_b = filter(clip_b)
filter_x_on_a = filter_x(clip_a)
filter_y_on_a = filter_y(clip_b)
此外,许多方法都在脚本模块或类似的集合中。 这些必须手动加载,然后在给定的别名下找到:
import vapoursynth as vs
core = vs.core
import awsmfunc as awf
import kagefunc as kgf
from vsutil import *
bbmod = awf.bbmod(...)
grain = kgf.adaptive_grain(...)
deband = core.f3kdb.Deband(...)
change_depth = depth(...)
为避免方法名冲突,通常不建议这样做 from x import *。
虽然此类模块中有许多filters,但也有一些filters可用作插件。
这些插件可以通过 core.namespace.plugin 或 替代调用 clip.namespace.plugin。
这意味着以下两个是等效的:
via_core = core.std.Crop(clip, ...)
via_clip = clip.std.Crop(...)
脚本里无法直接使用这些方法,这意味着以下是不可能的
not_possible = clip.awf.bbmod(...)
在本指南中,我们将会对要使用的源进行命名并设置变量名为 src 以方便之后反复对其操作。
在处理视频的过程中,通常会遇到一些视觉上的问题,如带状物、变暗的边框等。 由于这些东西在视觉上并不讨人喜欢,而且大多数情况下并不是原创作者的本意,所以最好使用视频过滤器来修复它们。
场景过滤
由于每个过滤器都有一定的破坏性,所以最好只在必要时应用它们。这通常是通过ReplaceFramesSimple完成的,它在RemapFrames插件中。
RemapFramesSimple也可以用Rfs调用。
另外,可以使用Python解决方案,例如std.Trim和addition。
然而,RemapFrames往往更快,特别是对于较大的替换映射集。
让我们看一个对100到200帧和500到750帧应用f3kdb解带过滤的例子:
src = core.ffms2.Source("video.mkv")
deband = source.neo_f3kdb.Deband(src)
replaced = core.remap.Rfs(src, deband, mappings="[100 200] [500 750]")
在插件和Python方法里有各种封装好的库,特别是前者的awsmfunc.rfs和后者的lvsfunc.util.replace_frames 。
过滤顺序
为了让滤镜正常工作,不至于产生反效果,按正确的顺序应用它们是很重要的。 这一点对于像debanders和graners这样的滤镜尤其重要,因为把它们放在调整大小之前会完全否定它们的效果。
一般可接受的顺序是:
- 载入视频 Load the source
- 裁剪 Crop
- 提高位深 Raise bit depth
- 除着色 Detint
- 修复脏线 Fix dirty lines
- 解块 Deblock
- 调整大小 Resize
- 降噪 Denoise
- 抗锯齿 Anti-aliasing
- 去晕 Dering (dehalo)
- 解带 Deband
- 颗粒 Grain
- 抖动到输出位深度 Dither to output bit depth
请记住,这只是一个一般的建议。 在某些情况下,你可能想偏离这个建议,例如,如果你使用的是KNLMeansCL这样的快速去噪器,你可以在调整大小之前做这个。
对于实拍内容来说,剪裁几乎总是必要的,因为黑条几乎总是应用于16:9的框架。
如果要裁剪的内容在每个方向上的分辨率都是2的倍数,这就是一个非常直接的过程。
crop = src.std.Crop(top=2, bottom=2, left=2, right=2)
然而,当情况不是这样时,事情就变得有点复杂了。 无论怎样,你都必须在继续操作前尽可能多地裁剪掉。
如果你使用的是完全黑白的影片,请阅读关于这些的附录条目。 下面的内容只适用于有颜色的视频。
然后,阅读本指南中脏线分章的FillBorders解释。
这将解释如果你不打算调整大小,该怎么做。
如果你打算调整大小。 根据 dirty lines 分章中的 调整大小说明 进行操作。
调整大小(Resizing)是一个非常复杂的话题。 然而,对于简单的downscaled压制,人们不需要知道太多信息。 因此,此页面将仅涵盖必要的downscaling说明。 那些有兴趣了解有关重采样的更多信息的人应该参考 Irrational Encoding Wizardry's guide's resampling page 以获取更多信息。
并且您可以查看后面的子章节以了解一些更高级的主题, 例如 解放缩(descaling)与重新缩放(rescaling) 或 色度重新采样(chroma resampling)和移动(shifting),这两者都是压制动画时绝对需要了解的。
Downscaling
对于downscaling, 首选的调整器是 spline36 调整器:
resize = src.resize.Spline36(1280, 720, dither_type="error_diffusion")
这里的参数应该很简单:只需根据需要调整宽度和高度。
不要担心 dither_type="error_diffusion",只需保持原样即可;它所做的只是让输出看起来更漂亮。
该参数的解释可以在 抖动(dithering) 章节中找到。
寻找目标尺寸
对于 16:9 内容,标准分辨率所需的尺寸应该是众所周知的: \(3840\times2160\) 是 2160p, \(1920\times1080\) 是 1080p, \(1280\times720\) 是 720p.
但是,大多数电影不是以这种纵横比制作的。 更常见的纵横比是 2.39:1,其中视频是 \(2048\times858\). 消费类产品通常采用上述分辨率,因此在裁剪黑条后更有可能看到 \(1920\times804\) 这种尺寸。
由此我们可以推算720p下的尺寸是 \(1280\times536\):
\[\begin{align} w &= \frac{720}{1080}\times1920=1280 \\ h &= \frac{720}{1080}\times804 =536 \end{align} \]
然而,情况并非总是如此。 假设您的视频源是 \(1920\times806\):
\[\begin{align} w &= \frac{720}{1080}\times1920=1280 \\ h &= \frac{720}{1080}\times806 =537.\overline{3} \end{align} \]
显然,我们不能调整大小至 \(537.\overline{3}\),因此我们需要找到具有最低纵横比误差的最接近的高度。 这里的解决方法是除以二,取整,然后再乘以二:
\[ h = \mathrm{round}\left( \frac{720}{1080} \times 806 \times \frac{1}{2} \right) \times 2 = 538 \]
在 Python 中:
height = round(1280 / src.width / 2 * src.height) * 2
现在,我们将其提供给我们的resize:
resize = src.resize.Spline36(1280, height, dither_type="error_diffusion")
或者,如果我们的源被裁剪在左侧和右侧而不是顶部和底部,我们会这样做:
width = round(720 / src.height / 2 * src.width) * 2
如果您不想为此烦恼, 您可以使用 awsmfunc 里封装好的 zresize 方法:
resize = awf.zresize(src, preset=720)
有了这个 preset 选项,您不必费心计算任何事情,只需说明目标分辨率(高度),它就会为您确定正确的尺寸。
笔记
如果调整不均匀源的大小, 请参阅 脏线(dirty lines) 章节, 特别是 填充边框(FillBorders) 部分和 笔记.
此外,值得注意的是,不应在脚本开始时调整大小,因为这样做会损坏执行的某些filtering,甚至重新引入问题。
理想的分辨率
对于动漫作品,请参阅 descaling subchapter 。 实拍场景中极少需要进行descaling,但如果您的来源特别模糊且明显是廉价制作,则值得研究。
众所周知,并非每个源都应以源的分辨率进行压制。 因此,人们应该知道来源是否有保证,例如从细节保留的角度来看,1080p 压制或 720p 压制就足够了。
为此,我们只需要先将源缩小再放大后进行简单比较:
downscale = src.resize.Spline36(1280, 720, dither_type="error_diffusion")
rescale = downscale.resize.Spline36(src.width, src.height, dither_type="error_diffusion")
现在,我们将两者交错,然后通过视频查看细节是否模糊:
out = core.std.Interleave([src, rescale])
我们还可以使用 awsmfunc 里封装的所有关于 UpscaleCheck 的方法:
out = awf.UpscaleCheck(src)
让我们看两个例子。 第一个,Shinjuku Swan II:

在这里,边缘在重新调整后变得非常模糊,这意味着 1080p 是有保证的。 这在植物的叶子中尤为明显。
第二个,The Way of the Dragon:

在这里,我们看到颗粒非常轻微地模糊,并且一些压缩产物被扭曲了。 但是,边缘和细节不受影响,这意味着 720p 在这里就可以了。
解放缩 Descaling
如果你读过一些关于压制动漫的文章,你可能听说过 "解放缩Descaling"这个词;这是一个通过找到原始分辨率和使用的调整内核来 "逆转" 拉伸的过程。 如果操作正确,这是一个近乎无损的过程,并产生比标准 Spline36 调整大小更清晰的输出,并减少光晕伪影。 然而,如果做得不对,这只会增加已经存在的问题,如光晕、振铃等。
最常用的反比例插件是Descale,它最容易通过fvsfunc调用,它对每个内核都有一个别名,例如fvf.Debilinear。
这支持双曲线、双线性、兰佐斯和样条曲线的升尺度。
大多数数字制作的动漫内容,特别是电视节目,都是由720p、810p、864p、900p或介于两者之间的双线性或双立方体升格而成。 虽然不是只有动漫可以做,但它在此类内容中更为普遍,所以我们将相应地关注动漫。
作为我们的例子,我们将看看Nichijou,它是一个从720p的双线升级。
为了展示解放缩的效果,让我们把它与标准的样条调整尺寸进行比较:
descale = fvf.Debilinear(src, 1280, 720)
spline = src.resize.Spline36(1280, 720)
out = core.std.Interleave([descale, spline])

原生分辨率和内核
现在,当你想解放缩时,你需要做的第一件事是弄清楚用什么来调整视频的大小,以及从哪个分辨率来调整大小。 这方面最流行的工具是getnative,它允许你给它提供一张图片,然后它将对其进行解放缩、调整大小,并计算出与来源的差异,然后绘制出结果,这样你就可以找到原始分辨率。
为了使其发挥最大的作用,你要找到一个明亮的画面,并有非常少的模糊、视觉效果、纹理等。
一旦你找到了一个,你就可以按以下方式运行脚本:
python getnative.py image.png -k bilinear
这将在Results目录下输出一个图形,并猜测其分辨率。
不过,自己看一下这个图是很有必要的。
在我们的例子中,这些是正确的参数,所以我们得到以下结果。

在720p时有一个明显的下降。 我们还可以测试其他内核:
python getnative.py image.png -k bicubic -b 0 -c 1
然后,该图看起来如下:

如果你想测试所有可能的内核,你可以使用--mode "all"。
为了仔细检查,我们将输入的帧与用相同内核放大的解放缩进行比较:
descale = fvf.Debilinear(src, 1280, 720)
rescale = descale.resize.Bilinear(src, src.width, src.height)
merge_chroma = rescale.std.Merge(src, [0, 1])
out = core.std.Interleave([src, merge_chroma])
在这里,我们将源头的色度与我们的重新缩放合并起来,因为色度的分辨率比源头的分辨率低,所以我们不能降低它的比例。 结果:

正如你所看到的,线性图实际上是相同的,没有引入额外的光晕或混叠。
另一方面,如果我们尝试一个不正确的内核和分辨率,我们会在重新缩放的图像中看到更多的伪影:
b, c = 0, 1
descale = fvf.Debicubic(src, 1440, 810, b=b, c=c)
rescale = descale.resize.Bicubic(src, src.width, src.height, filter_param_a=b, filter_param_b=c)
merge_chroma = rescale.std.Merge(src, [0, 1])
out = core.std.Interleave([src, merge_chroma])
混合分辨率
上面关于不正确的内核和高度的例子应该很明显,不正确的解放缩是相当有破坏性的。 不幸的是,大多数可以被解放缩的视频都有其他分辨率的元素。 有时,一帧中的不同元素会有不同的分辨率,例如,背景是900p的,人物A是810p的,人物B是720p的。 在这样的情况下,通常做一个简单的 spline36 调整大小是比较安全的。 从技术上讲,人们可以做大量的遮罩来解决这个问题,但这是一个很大的努力,而且遮罩很可能会失败。
一个更常见的会遇到混合分辨率的情况是片头和叠加,这通常是1080p的。 让我们来看看,如果我们在上面的画面中添加一些文字,并将其与 spline36 调整进行对比,会发生什么。 为了便于比较,这些图片被放大了3倍:

去线性调整在这里明显增加了更强的光晕伪影。
为了处理这个问题,我们可以使用fvsfunc中的DescaleM函数,它掩盖了这些元素,并通过 spline36 调整它们的大小。
descale = fvf.DebilinearM(src, 1280, 720)
由于这些函数相对较慢,你可能要考虑事先找到这些元素,并只对这些帧应用该函数。 如果你不确定你的帧没有1080p元素,但还是坚持使用这些函数。
另外,在非常罕见的情况下,分辨率和/或内核会逐个场景变化,甚至更糟,逐个帧变化。
你可以考虑试试lvsfunc.scale.descale,它试图为每一帧找到理想的高度。
然而,理想的情况是,你应该手动完成这个工作。
4:4:4 and 4:2:0
Upscaling and Rescaling
Upscaling
Rescaling
色度重采样与偏移(Chroma Resampling and Shifting)
位深 Bit Depths: 简介
当你过滤一个画面时,结果被限制在你的比特深度中的可用值。默认情况下,大多数SDR内容为8位,HDR内容为10位。在8位中,你被限制在0和255之间的值。然而,由于大多数视频内容是在有限的范围内,这个范围成为16至235(亮度)和16至240(色度)。
比方说,你想把数值在60到65之间的每个像素提高到0.88的幂。 四舍五入到小数点后3位。
| Original | Raised |
|---|---|
| 60 | 36.709 |
| 61 | 37.247 |
| 62 | 37.784 |
| 63 | 38.319 |
| 64 | 38.854 |
| 65 | 39.388 |
由于我们仅限于 0 到 255 之间的整数值,因此将这些四舍五入为 37、37、38、38、39、39。 因此,虽然过滤器不会导致相同的值,但我们将这些四舍五入为相同的值。 这会导致生成一些不需要的 色带(banding) 。 例如,提高到 8 位的 0.88 次方与 32 位的更高位深度:

为了缓解这种情况,我们在更高的位深度下工作,然后使用所谓的抖动算法在舍入期间添加一些波动并防止产生色带。 通常的位深度是 16 位和 32 位。 虽然 16 位一开始听起来更糟,但差异并不明显,并且 32 位,浮点数而不是整数格式,并不是每个过滤器都支持。
幸运的是,对于那些不在更高位深度下工作的人来说,许多过滤器在内部强制更高的精度并正确地抖动结果。 但是,多次在位深度之间切换会浪费 CPU 周期,并且在极端情况下还会改变图像。
更改位深 Changing bit depths
要在更高的位深度下工作,您可以在脚本filter部分的开头和结尾使用vsutil库中的 depth 方法。
这将在默认情况下使用高质量的抖动算法,而且只需按几下键盘。
from vsutil import depth
src = depth(src, 16)
resize = ...
my_great_filter = ...
out = depth(my_great_filter, 8)
当您在更高位深度下工作时,重要的是要记住,某些函数可能需要 8 位的参数输入值,而其他函数则需要输入位深度。 如果您在期望 16 位输入的函数中错误地输入假设为 8 位的 255,您的结果将大不相同,因为 255 是 8 位中较高的值,而在 16 位中,这大致相当于 8位 中的 1。
要转换值,你可以使用vsutil库中的 scale_value方法, 这将有助于处理边缘情况等:
from vsutil import scale_value
v_8bit = 128
v_16bit = scale_value(128, 8, 16)
得到 v_16bit = 32768, 16 位的中间点。
这对于 32 位浮点数并不那么简单,因为您需要指定是否根据范围缩放偏移量以及缩放亮度还是色度。
这是因为有限范围的亮度值介于 0 和 1 之间,而色度值介于 -0.5 和 +0.5 之间。
通常,您将处理电视范围,因此设置 scale_offsets=True:
from vsutil import scale_value
v_8bit = 128
v_32bit_luma = scale_value(128, 8, 32, scale_offsets=True)
v_32bit_chroma = scale_value(128, 8, 32, scale_offsets=True, chroma=True)
得到 v_32bit_luma = 0.5, v_32bit_chroma = 0.
Dither Algorithms
TODO
解带 Debanding
这是人们会遇到的最常见的问题。当码率不足(bitstarving)和糟糕的设置导致平滑的渐变变成突然的颜色变化时,通常会产生色带,这显然会让画面看起来很糟糕。这些可以通过执行类似模糊的操作并限制它们的输出来修复。
请注意,由于模糊是一个非常具有破坏性的过程,因此建议仅将其应用于视频的必要部分并使用 蒙版(masks)来进一步限制更改。
VapourSynth 有三个很棒的工具可以用来修复色带:neo_f3kdb, fvsfunc内置的蒙版 gradfun3 和 vs-placebo的 placebo.Deband。

使用 f3kdb 默认设置修复了色带示例
neo_f3kdb
deband = core.neo_f3kdb.deband(src=clip, range=15, y=64, cb=64, cr=64, grainy=64, grainc=64, dynamic_grain=False, sample_mode=2)
这些设置对某些人来说可能不言自明,但它们的作用如下:
-
src这显然是您的剪辑源。 -
range这指定了用于计算某物是否有条带的像素范围。更大的范围意味着更多的像素用于计算,这意味着它需要更多的处理能力。默认值 15 通常应该没问题。提高此值可能有助于使步长较小的较大梯度看起来更平滑,而较低的值将有助于捕获较小的实例。 -
y最重要的设置,因为大多数(明显的)条带发生在亮度平面上。它指定了亮度平面上的某些东西被认为是色带的差异必须有多大。你应该从低而缓慢的开始,但一定要建立这个直到条带消失。如果设置得太高,很多细节会被视为条带,因此会变得模糊。 根据您的采样模式,值将仅以 16(mode 2)或 32(mode 1、3、4)的步长产生影响。这意味着 y=20 等价于 y=30。 -
cb和cr除了色度外与y都是一样的。 但是,色度平面上的色带相对不常见,因此您通常可以将其关闭。 -
grainy和grainc为了防止色带再次发生并抵消平滑,通常在解带后添加颗粒。但是,由于这种假颗粒非常明显,因此建议保守一些。 或者,您可以使用自定义颗粒生成器,这将为您提供更好的输出 (有关更多信息,请参阅 粒化部分)。 -
dynamic_grain默认情况下,由f3kdb添加的颗粒是静态的,这压缩得更好,因为显然变化较少,但它通常看起来与实况内容无关,因此通常建议将其设置为True,除非您正在处理动画内容。 -
sample_mode在README中有说明。因为它可能具有较少的细节损失,可以考虑切换到 4。
深入讲解
TODOGradFun3
gradfun3是 f3kdb 的最受欢迎替代品。 这个函数需要更多的资源和不那么直接的参数,但在一些 f3kdb 处理不好的地方表现不错:
import fvsfunc as fvf
deband = fvf.GradFun3(src, thr=0.35, radius=12, elast=3.0, mask=2, mode=3, ampo=1, ampn=0, pat=32, dyn=False, staticnoise=False, smode=2, thr_det=2 + round(max(thr - 0.35, 0) / 0.3), debug=False, thrc=thr, radiusc=radius, elastc=elast, planes=list(range(src.format.num_planes)), ref=src, bits=src.format.bits_per_sample) # + resizing variables
fmtconv中许多设置的值都是给位深转换或解放缩使用的, 这两者在这里都不相关。这里真正感兴趣的值是:
-
thr等价于y,cb, 和cr的作用。您可能想要提高或降低它。 -
radius具有和f3kdb的range相同的效果。 -
smode设置平滑模式。通常最好保留默认值,如果您想使用支持 CUDA 的 GPU 而不是 CPU,则设置为 5。使用ref(默认为剪辑输入) 作为参考剪辑。 -
mask设置遮罩强度。 0 禁用。 默认值是一个合理的值。 -
planes置应处理哪些平面。 -
debug允许您查看遮罩。 -
elast控制去色带和剪辑源之间的混合。默认值是一个合理的值。 较高的值优先考虑去色带。
深入讲解
TODO 要更深入地解释 `thr` 和 `elast` 的作用, 请查看mvsfunc的算法解释.
placebo.Deband
这个 debander 对 VapourSynth 来说很新,但它非常擅长修复强条带。然而,同样地,它也容易出现不必要的细节损失,因此应该只在必要时使用,并且最好与细节/边缘蒙版结合使用。它的(当前)参数:
placebo.Deband(clip clip[, int planes = 1, int iterations = 1, float threshold = 4.0, float radius = 16.0, float grain = 6.0, int dither = True, int dither_algo = 0])
这个功能在未来不太可能发生重大变化,因此非常值得读一读 the README 。
您要查看的参数:
-
planes显然是要加工的平面。此处的语法不同,请查看README。简而言之,默认仅对亮度,1 | 2 | 4对亮度和色度。 -
iterations设置 debander 循环的频率。 不建议更改默认设置,尽管这在极端情况下很有用。 -
threshold设置 debander 的强度或更改像素时的阈值。尽量不要超过 12。如果会,请以 1 为步长进行微调。 -
radius与之前的功能相同。 -
grain同样与f3kdb的一样, 但是颗粒更好。
深入讲解
TODO 它使用了 mpv debander,只是平均一个范围内的像素,如果差异低于阈值,则输出平均值。该算法在 中进行了解释.色带检测 Banding detection
如果要自动检测色带,可以使用awsmfunc中的 banddtct 。 确保正确调整值并检查完整输出。查看 此链接 以获取有关如何使用它的说明。您也可以只运行 adptvgrnMod 或用一个高的luma_scaling值来运行 adaptive_grain 以期望颗粒可以完全覆盖它。更多信息在
粒化部分。请注意,这两种方法都无法检测/修复所有类型的色带。 banddtct 找不到被颗粒覆盖的色带,而且用于修复色带的纹理仅适用于较小的实例。
解块 Deblocking

解块相当于平滑输入源,通常是在画面顶部使用另一个蒙版。 最常用的是havsfunc中的 Deblock_QED 函数。
主要参数是
-
quant1: 边缘解块的强度。 默认值为 24。您可能希望显着提高此值。 -
quant2: 内部解块的强度。 默认值为 26。同样,提高此值可能会有益。
深入讲解
TODO其他常用的选项是 deblock.Deblock,它非常强大,几乎总是有效
深入讲解
TODOdfttest.DFTTest, 相对较弱,但非常暴力,还有
fvf.AutoDeblock, 对于 MPEG-2 源的解块非常有用,并且可以应用于整个视频。另一种流行的方法是简单地解带,因为解块和解带非常相似。这对于 AVC 蓝光源是一个不错的选择。
深入讲解
TODO颗粒化
TODO: 解释为什么我们这么喜欢颗粒,以及静态与动态颗粒。 还有,图像。
颗粒过滤器
你可以用几个不同的过滤器来颗粒化。 由于很多函数的工作原理类似,我们将只介绍AddGrain和libplacebo颗粒。
AddGrain
这个插件允许你以不同的强度和颗粒模式在luma和chroma颗粒中添加颗粒。
grain = src.grain.Add(var=1.0, uvar=0.0, seed=-1, constant=False)
这里,var设置luma面的颗粒强度,uvar设置chroma面的强度。
seed允许你指定一个自定义的颗粒模式,如果你想多次复制一个颗粒模式,例如用于比较编码,这很有用。
constant允许你在静态和动态纹理之间进行选择。
提高强度既可以增加颗粒的数量,也可以增加颗粒像素与原始像素的偏移。 例如,`var=1'会导致数值与输入值相差3个8位数。
直接使用这个函数没有实际意义,但知道它的作用是很好的,因为它被认为是常用的颗粒器。
深入解释
这个插件使用正态分布来寻找它改变输入的值。 参数 `var` 是正态分布的标准差 (通常记做 \(\sigma\)) 。这意味着 (这些都是近似值):
- \(68.27\%\) 的输出像素值在输入值的 \(\pm1\times\mathtt{var}\) 倍以内
- \(95.45\%\) 的输出像素值在输入值的 \(\pm2\times\mathtt{var}\) 倍以内
- \(99.73\%\) 的输出像素值在输入值的 \(\pm3\times\mathtt{var}\) 倍以内
- \(50\%\) 的输出像素值在输入值的 \(\pm0.675\times\mathtt{var}\) 倍以内
- \(90\%\) 的输出像素值在输入值的 \(\pm1.645\times\mathtt{var}\) 倍以内
- \(95\%\) 的输出像素值在输入值的 \(\pm1.960\times\mathtt{var}\) 倍以内
- \(99\%\) 的输出像素值在输入值的 \(\pm2.576\times\mathtt{var}\) 倍以内
placebo.Deband as a grainer
另外,只用placebo.Deband作为一个颗粒器,也能带来一些不错的结果。
grain = placebo.Deband(iterations=0, grain=6.0)
这里的主要优势是它在你的GPU上运行,所以如果你的GPU还没有忙于其他的过滤器,使用这个可以让你的速度略有提高。
深入解释
TODOadaptive_grain
这个函数来自kagefunc,根据整体帧亮度和单个像素亮度应用AddGrain。
这对于掩盖小的条带和/或帮助x264将更多的比特分配给暗部非常有用。
grain = kgf.adaptive_grain(src, strength=.25, static=True, luma_scaling=12, show_mask=False)
这里的强度是AddGrain的var。
默认值或稍低的值通常是好的。
你可能不希望超过0.75。
luma_scaling参数用于控制它对暗色帧的偏爱程度,即较低的luma_scaling将对亮色帧应用更多的纹理。
你可以在这里使用极低或极高的值,这取决于你想要什么。
例如,如果你想对所有的帧进行明显的纹理处理,你可以使用luma_scaling=5,而如果你只想对较暗的帧的暗部进行纹理处理以掩盖轻微的带状物,你可以使用luma_scaling=100。
show_mask显示用于应用纹理的遮罩,越白意味着应用的纹理越多。
建议在调整luma_scaling时打开它。
深入解释
该方法的作者写了一篇精彩的博文,解释了该函数和它的工作原理。GrainFactory3
TODO:重写或直接删除它。
作为kgf.adaptive_grain的一个较早的替代品,havsfunc的GrainFactory3仍然相当有趣。
它根据像素值的亮度将其分成四组,并通过AddGrain将不同大小的颗粒以不同的强度应用于这些组。
grain = haf.GrainFactory3(src, g1str=7.0, g2str=5.0, g3str=3.0, g1shrp=60, g2shrp=66, g3shrp=80, g1size=1.5, g2size=1.2, g3size=0.9, temp_avg=0, ontop_grain=0.0, th1=24, th2=56, th3=128, th4=160)
参数的解释在源代码上面。
这个函数主要是在你想只对特定的帧应用颗粒时有用,因为如果对整个视频应用颗粒,应该考虑整体的帧亮度。
例如,GrainFactory3 可以弥补左右边框的颗粒缺失:

深入解释
TODO简而言之:为每个亮度组创建一个蒙版,使用双曲线调整大小,用锐度控制b和c来调整纹理的大小,然后应用这个。 时间平均法只是使用misc.AverageFrames对当前帧和其直接邻接的纹理进行平均。
adptvgrnMod
这个函数以GrainFactory3的方式调整颗粒大小,然后使用adaptive_grain的方法进行应用。
它还对暗部和亮部进行了一些保护,以保持平均帧亮度。
grain = agm.adptvgrnMod(strength=0.25, cstrength=None, size=1, sharp=50, static=False, luma_scaling=12, seed=-1, show_mask=False)
颗粒强度由luam的strength和chroma的cstrength控制。
cstrength默认为strength的一半。
就像adaptive_grain一样,默认值或稍低的值通常是好的,但你不应该太高。
如果你使用的size大于默认值,你可以用更高的值,例如strength=1,但还是建议对颗粒应用保持保守。
size and sharp 参数允许你使应用的颗粒看起来更像电影的其他部分。
建议对这些参数进行调整,以便使假的颗粒不会太明显。
在大多数情况下,你会想稍微提高这两个参数,例如:size=1.2, sharp=60。
static、luma_scaling和show_mask等同于adaptive_grain,所以看上面的解释。
seed与AddGrain的相同;同样,向上面解释。
默认情况下,adptvgrnMod会淡化极值(16或235)附近的纹理和灰色的阴影。
这些功能可以通过设置fade_edges=False和protect_neutral=False分别关闭。
最近,用这个功能从一个人的磨光机中完全去除颗粒,并将磨光的区域完全磨光,这已成为普遍的做法。
sizedgrn
如果想禁用基于亮度的应用,可以使用sizedgrn,它是adptvgrnMod中的内部粒度函数。
一些 adptvgrnMod 与 sizedgrn 对比的例子,供好奇的人参考
一个明亮的场景,基于亮度的应用产生了很大的差异:

一个整体较暗的场景,其中的差异要小得多:

一个黑暗的场景,在画面中的每一个地方都均匀地(几乎)应用了颗粒:

深入解释
(该功能的作者的旧文。)Size and Sharpness
adptvgrnMod的颗粒化部分与GrainFactory3的相同;它在尺寸参数定义的分辨率下创建一个 "空白"(比特深度的中间点)剪辑,然后通过一个使用由sharp决定的b和c值的二次方内核进行扩展:
$$\mathrm{grain\ width} = \mathrm{mod}4 \left( \frac{\mathrm{clip\ width}}{\mathrm{size}} \right)$$
例如,一个1920x1080的片段,尺寸值为1.5:
$$ \mathrm{mod}4 \left( \frac{1920}{1.5} \right) = 1280 $$
这决定了颗粒器所操作的帧的大小。
现在,决定使用bicubic kernel的参数:
$$ b = \frac{\mathrm{sharp}}{-50} + 1 $$ $$ c = \frac{1 - b}{2} $$
这意味着,对于默认的50的锐度,使用的是Catmull-Rom过滤器:
$$ b = 0, \qquad c = 0.5 $$
Values under 50 will tend towards B-Spline (b=1, c=0), while ones above 50 will tend towards b=-1, c=1. As such, for a Mitchell (b=1/3, c=1/3) filter, one would require sharp of 100/3.
The grained "blank" clip is then resized to the input clip's resolution with this kernel. If size is greater than 1.5, an additional resizer call is added before the upscale to the input resolution:
$$ \mathrm{pre\ width} = \mathrm{mod}4 \left( \frac{\mathrm{clip\ width} + \mathrm{grain\ width}}{2} \right) $$
With our resolutions so far (assuming we did this for size 1.5), this would be 1600. This means with size 2, where this preprocessing would actually occur, our grain would go through the following resolutions:
$$ 960 \rightarrow 1440 \rightarrow 1920 $$
Fade Edges
The fade_edges parameter introduces the option to attempt to maintain overall average image brightness, similar to ideal dithering. It does so by limiting the graining at the edges of the clip's range. This is done via the following expression:
x y neutral - abs - low < x y neutral - abs + high > or
x y neutral - x + ?
Here, x is the input clip, y is the grained clip, neutral is the midway point from the previously grained clip, and low and high are the edges of the range (e.g. 16 and 235 for 8-bit luma). Converted from postfix to infix notation, this reads:
\[x = x\ \mathtt{if}\ x - \mathrm{abs}(y - neutral) < low\ \mathtt{or}\ x - \mathrm{abs}(y - neutral) > high\ \mathtt{else}\ x + (y - neutral)\]
The effect here is that all grain that wouldn't be clipped during output regardless of whether it grains in a positive or negative direction remains, while grain that would pass the plane's limits isn't taken.
In addition to this parameter, protect_neutral is also available. This parameter protects "neutral" chroma (i.e. chroma for shades of gray) from being grained. To do this, it takes advantage of AddGrainC working according to a Guassian distribution, which means that $$max\ value = 3 \times \sigma$$ (sigma being the standard deviation - the strength or cstrength parameter) is with 99.73% certainty the largest deviated value from the norm (0). This means we can perform a similar operation to the one for fade_edges to keep the midways from being grained. To do this, we resize the input clip to 4:4:4 and use the following expression:
\[\begin{align}x \leq (low + max\ value)\ \mathtt{or}\ x \geq (high - max\ value)\ \mathtt{and}\\ \mathrm{abs}(y - neutral) \leq max\ value\ \mathtt{and}\ \mathrm{abs}(z - neutral) \leq max\ value \end{align}\]
With x, y, z being each of the three planes. If the statement is true, the input clip is returned, else the grained clip is returned.
I originally thought the logic behind protect_neutral would also work well for fade_edges, but I then realized this would completely remove grain near the edges instead of fading it.
Now, the input clip and grained clip (which was merged via std.MergeDiff, which is x - y - neutral) can be merged via the adaptive_grain mask.

来自 A Silent Voice (2016)的前奏的脏线。鼠标移上去: 用ContinuityFixer和FillBorders修复。
你可能会遇到的一个更常见的问题是 "脏线",这通常是在视频的边界上发现的,其中一排或一列的像素表现出与周围环境不一致的亮度值。通常情况下,这是由于不当的downscaling,例如在添加边框后downscaling。脏线也可能发生,因为压缩者没有考虑到他们在使用4:2:2色度子采样时(意味着他们的高度不必是mod2),消费者的视频将是4:2:0,导致额外的黑行,如果主片段没有正确放置,你就无法在裁剪时摆脱。另一种形式的脏线是在黑条上出现色度平面时表现出来的。通常情况下,这些应该被裁剪掉。然而,相反的情况也可能发生,即具有合法的 luma 信息的平面缺乏色度信息。
重要的是要记住,有时你的来源会有假行(通常被称为 "死"行),也就是没有合法信息的行。这些通常只是镜像下一行/一列。不要麻烦地修复这些,只需裁剪它们。一个例子:

同样,当你试图修复脏线时,你应该彻底检查你的修复没有引起不必要的问题,如涂抹(常见于过度热心的ContinuityFixer值)或闪烁(特别是在片头,在大多数情况下,建议从你的修复中省略片头卷)。如果你不能找出适当的修复方法,完全可以裁剪掉脏线或不修复。糟糕的修复比没有修复更糟糕
这里有五种常用的修复脏线的方法:
rektlvls
来自rekt。这基本上是AviSynth的 FixBrightnessProtect3 和 FixBrightness 的合二为一,尽管与 FixBrightness 不同,不是对整个画面进行处理。它的数值很直接。提高调整值是为了变亮,降低是为了变暗。将prot_val设置为None,它的功能就像FixBrightness,意味着调整值需要改变。
from rekt import rektlvls
fix = rektlvls(src, rownum=None, rowval=None, colnum=None, colval=None, prot_val=[16, 235])
如果你想一次处理多行,你可以输入一个列表 (例如 rownum=[0, 1, 2]).
为了说明这一点,让我们看看《寄生虫》(2017)的黑白蓝光中的脏线。寄生虫(2019)的底层行的黑白蓝光:

在这个例子中,最下面的四行有交替的亮度 与下两行的偏移量。所以,我们可以用rektlvls来提高 提高第一行和第三行的luma,然后再降低第二行和第四行的luma。在第二和第四行中降低。
fix = rektlvls(src, rownum=[803, 802, 801, 800], rowval=[27, -10, 3, -3])
在这种情况下,我们处于FixBrightnessProtect3模式。我们在这里没有利用prot_val的优势,但人们通常会使用这种模式,因为总有机会帮助我们。结果是:

深入解释
InFixBrightness mode, this will perform an adjustment with
std.Levels on the desired row. This means that, in 8-bit,
every possible value \(v\) is mapped to a new value according to the
following function:
$$\begin{aligned}
&\forall v \leq 255, v\in\mathbb{N}: \\
&\max\left[\min\left(\frac{\max(\min(v, \texttt{max_in}) - \texttt{min_in}, 0)}{(\texttt{max_in} - \texttt{min_in})}\times (\texttt{max_out} - \texttt{min_out}) + \texttt{min_out}, 255\right), 0\right] + 0.5
\end{aligned}$$
For positive adj_val,
\(\texttt{max_in}=235 - \texttt{adj_val}\). For negative ones,
\(\texttt{max_out}=235 + \texttt{adj_val}\). The rest of the values
stay at 16 or 235 depending on whether they are maximums or
minimums.
FixBrightnessProtect3 mode takes this a bit further, performing
(almost) the same adjustment for values between the first
\(\texttt{prot_val} + 10\) and the second \(\texttt{prot_val} - 10\),
where it scales linearly. Its adjustment value does not work the
same, as it adjusts by \(\texttt{adj_val} \times 2.19\). In 8-bit:
Line brightening: $$\begin{aligned} &\texttt{if }v - 16 <= 0 \\ &\qquad 16 / \\ &\qquad \texttt{if } 235 - \texttt{adj_val} \times 2.19 - 16 <= 0 \\ &\qquad \qquad 0.01 \\ &\qquad \texttt{else} \\ &\qquad \qquad 235 - \texttt{adj_val} \times 2.19 - 16 \\ &\qquad \times 219 \\ &\texttt{else} \\ &\qquad (v - 16) / \\ &\qquad \texttt{if }235 - \texttt{adj_val} \times 2.19 - 16 <= 0 \\ &\qquad \qquad 0.01 \\ &\qquad \texttt{else} \\ &\qquad \qquad 235 - \texttt{adj_val} \times 2.19 - 16 \\ &\qquad \times 219 + 16 \end{aligned}$$
Line darkening: $$\begin{aligned} &\texttt{if }v - 16 <= 0 \\ &\qquad\frac{16}{219} \times (235 + \texttt{adj_val} \times 2.19 - 16) \\ &\texttt{else} \\ &\qquad\frac{v - 16}{219} \times (235 + \texttt{adj_val} \times 2.19 - 16) + 16 \\ \end{aligned}$$
All of this, which we give the variable \(a\), is then protected by (for simplicity's sake, only doing dual prot_val, noted by \(p_1\) and \(p_2\)):
$$\begin{aligned}
& a \times \min \left[ \max \left( \frac{v - p_1}{10}, 0 \right), 1 \right] \\
& + v \times \min \left[ \max \left( \frac{v - (p_1 - 10)}{10}, 0 \right), 1 \right] \times \min \left[ \max \left( \frac{p_0 - v}{-10}, 0\right), 1 \right] \\
& + v \times \max \left[ \min \left( \frac{p_0 + 10 - v}{10}, 0\right), 1\right]
\end{aligned}$$
bbmod
来自awsmfunc。 这是原BalanceBorders函数的一个模子。虽然它不能像rektlvls那样保留原始数据,但在高blur和thresh值的情况下,它可以产生很好的结果,而且很容易用于多行,特别是具有不同亮度的行,rektlvls就不再有用。如果它不能产生像样的结果,可以改变这些值,但是你设置得越低,这个函数的破坏性就越大。它也比havsfunc和sgvsfunc中的版本快得多,因为只有必要的像素被处理。
import awsmfunc as awf
bb = awf.bbmod(src=clip, left=0, right=0, top=0, bottom=0, thresh=[128, 128, 128], blur=[20, 20, 20], planes=[0, 1, 2], scale_thresh=False, cpass2=False)
thresh和blur的数组同样是y、u和v值。
建议首先尝试 blur=999,然后降低它和 thresh,直到你得到合适的值。
thresh 指定了结果与输入值的差异程度。这意味着这个值越低越好。blur是过滤器的强度,数值越低越强,数值越大越不积极。如果你设置blur=1,你基本上是在复制行。如果你在色度方面有问题,你可以尝试激活cpass2,但要注意这需要设置一个非常低的thresh,因为这大大改变了色度处理,使其相当激进。
对于我们的例子,我已经创建了假的脏线,我们将修复它:

为了解决这个问题,我们可以应用bbmod,用低模糊度和高阈值。
这意味着像素值会有很大的变化:
fix = awf.bbmod(src, top=6, thresh=90, blur=20)

我们的输出已经非常接近于我们假设的源文件的样子了。与rektlvls不同,这个函数使用起来相当快,所以懒人(即每个人)可以在调整大小之前用它来修复脏线,因为在调整大小之后,差别不会很明显。
虽然你可以根据需要在许多行/列上使用rektlvls,但对bbmod来说却不是如此。 除非你之后调整大小,否则对于低的 blur 值(\(\approx 20\)),你应该只在两行/像素上使用bbmod,对于高的 blur 值,你应该使用三行/像素。如果你是之后调整大小,你可以根据以下情况改变最大值:
\[
max_\mathrm{resize} = max \times \frac{resolution_\mathrm{source}}{resolution_\mathrm{resized}}
\]
深入解释
bbmod works by blurring the desired rows, input rows, and
reference rows within the image using a blurred bicubic kernel,
whereby the blur amount determines the resolution scaled to accord
to \(\mathtt{\frac{width}{blur}}\). The output is compared using
expressions and finally merged according to the threshold specified.
The function re-runs one function for the top border for each side by flipping and transposing. As such, this explanation will only cover fixing the top.
First, we double the resolution without any blurring (\(w\) and \(h\) are input clip's width and height): \[ clip_2 = \texttt{resize.Point}(clip, w\times 2, h\times 2) \]

Now, the reference is created by cropping off double the to-be-fixed number of rows. We set the height to 2 and then match the size to the double res clip: \[\begin{align} clip &= \texttt{CropAbs}(clip_2, \texttt{width}=w \times 2, \texttt{height}=2, \texttt{left}=0, \texttt{top}=top \times 2) \\ clip &= \texttt{resize.Point}(clip, w \times 2, h \times 2) \end{align}\]

Before the next step, we determine the \(blurwidth\): \[ blurwidth = \max \left( 8, \texttt{floor}\left(\frac{w}{blur}\right)\right) \] In our example, we get 8.
Now, we use a blurred bicubic resize to go down to \(blurwidth \times 2\) and back up: \[\begin{align} referenceBlur &= \texttt{resize.Bicubic}(clip, blurwidth \times 2, top \times 2, \texttt{b}=1, \texttt{c}=0) \\ referenceBlur &= \texttt{resize.Bicubic}(referenceBlur, w \times 2, top \times 2, \texttt{b}=1, \texttt{c}=0) \end{align}\]


Then, crop the doubled input to have height of \(top \times 2\): \[ original = \texttt{CropAbs}(clip_2, \texttt{width}=w \times 2, \texttt{height}=top \times 2) \]

Prepare the original clip using the same bicubic resize downwards: \[ clip = \texttt{resize.Bicubic}(original, blurwidth \times 2, top \times 2, \texttt{b}=1, \texttt{c}=0) \]

Our prepared original clip is now also scaled back down: \[ originalBlur = \texttt{resize.Bicubic}(clip, w \times 2, top \times 2, \texttt{b}=1, \texttt{c}=0) \]

Now that all our clips have been downscaled and scaled back up, which is the blurring process that approximates what the actual value of the rows should be, we can compare them and choose how much of what we want to use. First, we perform the following expression (\(x\) is \(original\), \(y\) is \(originalBlur\), and \(z\) is \(referenceBlur\)): \[ \max \left[ \min \left( \frac{z - 16}{y - 16}, 8 \right), 0.4 \right] \times (x + 16) + 16 \] The input here is: \[ balancedLuma = \texttt{Expr}(\texttt{clips}=[original, originalBlur, referenceBlur], \texttt{"z 16 - y 16 - / 8 min 0.4 max x 16 - * 16 +"}) \]

What did we do here? In cases where the original blur is low and supersampled reference's blur is high, we did: \[ 8 \times (original + 16) + 16 \] This brightens the clip significantly. Else, if the original clip's blur is high and supersampled reference is low, we darken: \[ 0.4 \times (original + 16) + 16 \] In normal cases, we combine all our clips: \[ (original + 16) \times \frac{originalBlur - 16}{referenceBlur - 16} + 16 \]
We add 128 so we can merge according to the difference between this and our input clip: \[ difference = \texttt{MakeDiff}(balancedLuma, original) \]
Now, we compare to make sure the difference doesn't exceed \(thresh\): \[\begin{align} difference &= \texttt{Expr}(difference, "x thresh > thresh x ?") \\ difference &= \texttt{Expr}(difference, "x thresh < thresh x ?") \end{align}\]
These expressions do the following: \[\begin{align} &\texttt{if }difference >/< thresh:\\ &\qquad thresh\\ &\texttt{else}:\\ &\qquad difference \end{align}\]
This is then resized back to the input size and merged using MergeDiff back into the original and the rows are stacked onto the input. The output resized to the same res as the other images:

FillBorders
来自fb。 这个函数几乎就是复制下一列/行的内容。
虽然这听起来很傻,但当降频导致更多的行在底部而不是顶部,并且由于YUV420的mod2高度,我们必须填补一个行时,它就会非常有用。
fill = core.fb.FillBorders(src=clip, left=0, right=0, bottom=0, top=0, mode="fixborders")
这个函数的一个非常有趣的用途是类似于只对色度平面应用ContinuityFixer,它可以用于灰色边界或无论应用什么luma修复都与周围环境不匹配的边界。这可以用下面的脚本来完成:
fill = core.fb.FillBorders(src=clip, left=0, right=0, bottom=0, top=0, mode="fixborders")
merge = core.std.Merge(clipa=clip, clipb=fill, weight=[0,1])
你也可以分割平面,单独处理色度平面,尽管这样做只是稍微快一点。在awsmfunc中重新封装了FillBorders,它允许你为fb指定每个平面的值。
注意,你应该只用FillBorders来填充单列/行。 如果你有更多的黑线,请裁剪它们 如果视频中存在需要不同裁剪的帧,不要把这些填满。 本章末尾会有更多这方面的内容。
为了说明需要FillBorders的片源可能是什么样子,让我们再次看看Parasite (2019)的SDR UHD,它需要不均匀地裁剪277。然而,由于色度子采样,我们不能裁剪,所以我们需要填补一行。为了说明这一点,我们将只看最上面的几行。根据色度子采样进行裁剪,我们可以得到:
crp = src.std.Crop(top=276)

很明显,我们想去掉顶部的黑线,所以让我们对它使用FillBorders:
fil = crp.fb.FillBorders(top=1, mode="fillmargins")

这看起来已经比较好了,但是橙色的色调看起来被洗掉了。
这是因为FillBorders在两个的luma被固定的情况下只能填充一个chroma。所以,我们也需要填充色度。为了使这个更容易写,让我们使用awsmfunc内封装的。
fil = awf.fb(crp, top=1)

我们的来源现在已经固定了。有些人可能想调整色度的大小,以保持原来的长宽比,对色度进行有损重采样,但这是否是一种方式,一般没有共识。如果你想走这条路:
top = 1
bot = 1
new_height = crp.height - (top + bot)
fil = awf.fb(crp, top=top, bottom=bot)
out = fil.resize.Spline36(crp.width, new_height, src_height=new_height, src_top=top)
深入解释
FillBorders has four modes, although we only really care about mirror, fillmargins, and fixborders.
The mirror mode literally just mirrors the previous pixels. Contrary to the third mode, repeat, it doesn't just mirror the final row, but the rows after that for fills greater than 1. This means that, if you only fill one row, these modes are equivalent. Afterwards, the difference becomes obvious.
In fillmargins mode, it works a bit like a convolution, whereby for rows it does a [2, 3, 2] of the next row's pixels, meaning it takes 2 of the left pixel, 3 of the middle, and 2 of the right, then averages. For borders, it works slightly differently: the leftmost pixel is just a mirror of the next pixel, while the eight rightmost pixels are also mirrors of the next pixel. Nothing else happens here.
The fixborders mode is a modified fillmargins that works the same for rows and columns. It compares fills with emphasis on the left, middle, and right with the next row to decide which one to use.
ContinuityFixer
来自cf。 ContinuityFixer的工作方式是将指定的行/列与周围range指定的行/列数量进行比较,通过最小二乘法回归找到新的数值。结果与bbmod相似,但它创建的数据完全是假的,所以最好使用rektlvls或bbmod来代替高模糊度。它的设置看起来如下:
fix = core.cf.ContinuityFixer(src=clip, left=[0, 0, 0], right=[0, 0, 0], top=[0, 0, 0], bottom=[0, 0, 0], radius=1920)
这是假设你使用的是1080p的素材,因为radius的值被设置为源的分辨率所定义的最长的一组。我推荐一个更低的值,但不要低于3,因为在这一点上,你可能是在复制像素(见下面的FillBorders)。可能会让大多数新手感到困惑的是我所输入的行/列固定值的数组。这些值表示要应用于三个平面的值。通常情况下,脏线只发生在luma平面上,所以你可以把其他两个平面的值保持为0。请注意,数组不是必须的,所以你也可以直接输入你想要修复的行/列的数量,所有平面都会被处理。
由于ContinuityFixer不太可能保持原始数据,建议优先使用bbmod而不是它。
让我们再看一下bbmod的例子,并应用ContinuityFixer:
fix = src.cf.ContinuityFixer(top=[6, 6, 6], radius=10)

让我们把这个和bbmod的修复进行比较(记得鼠标移到上面去比较):
ContinuityFixer 稍微好一点。
这种情况很少发生,因为`ContinuityFixer`往往比`bbmod`更具破坏性。
就像bbmod一样,ContinuityFixer不应该被用于超过两行/列。 同样,如果你要调整大小,你可以相应改变这个最大值:
\[
max_\mathrm{resize} = max \times \frac{resolution_\mathrm{source}}{resolution_\mathrm{resized}}
\]
深入解释
ContinuityFixer works by calculating the least squares
regression of the pixels within the radius. As such, it creates
entirely fake data based on the image's likely edges. No special explanation here.
ReferenceFixer
来自edgefixer。 这需要原始版本的edgefixer(cf只是它的一个旧的移植版本,但它更好用,而且处理过程没有改变)。我从来没有发现它有什么用处,但在理论上,它是相当整洁的。它与参考素材进行比较,以调整其边缘固定,就像在ContinuityFixer中一样。
fix = core.edgefixer.Reference(src, ref, left=0, right=0, top=0, bottom=0, radius = 1920)
笔记
太多的行/列
有一点不应该被忽视的是,将这些修正(除了rektlvls)应用于太多的行/列,可能会导致这些行/列在最终结果上看起来模糊不清。正因为如此,建议尽可能使用rektlvls,或者只在必要的行上仔细应用轻量级的修正。如果失败了,最好在使用 "ContinuityFixer "之前尝试一下bbmod。
调整大小
值得注意的是,在调整大小之前,你应该始终修复脏线,因为不这样做会引入更多的脏线。然而,重要的是要注意,如果你在一个边缘有一条黑线,你可以使用FillBorders,你应该用你的调整器把它删除。
例如,要将一个顶部有一条填充线的剪辑从\(1920\times1080\)到\(1280\times536\):
top_crop = 138
bot_crop = 138
top_fill = 1
bot_fill = 0
src_height = src.height - (top_crop + bot_crop) - (top_fill + bot_fill)
crop = core.std.Crop(src, top=top_crop, bottom=bot_crop)
fix = core.fb.FillBorders(crop, top=top_fill, bottom=bot_fill, mode="fillmargins")
resize = core.resize.Spline36(1280, 536, src_top=top_fill, src_height=src_height)
对角线的边框
如果你要处理对角线的边框,这里正确的做法是屏蔽边框区域,用FillBorders调用来合并源。这方面的一个例子 (来自 你的名字 (2016)):

修正在填充边缘模式下与未填充的比较,并调整对比度以获得清晰的效果:

使用的代码(注意,这是除着色后的结果):
mask = core.std.ShufflePlanes(src, 0, vs.GRAY).std.Binarize(43500)
cf = core.fb.FillBorders(src, top=6, mode="mirror").std.MaskedMerge(src, mask)
寻找脏线
脏线可能相当难以发现。如果你在检查随机框架的边框时没有立即发现任何问题,那么你很可能会没事。如果你知道有一些框架的每一面都有小的黑色边框,你可以使用类似以下脚本的东西:
def black_detect(clip, thresh=None):
if thresh:
clip = core.std.ShufflePlanes(clip, 0, vs.GRAY).std.Binarize(
"{0}".format(thresh)).std.Invert().std.Maximum().std.Inflate( ).std.Maximum().std.Inflate()
l = core.std.Crop(clip, right=clip.width / 2)
r = core.std.Crop(clip, left=clip.width / 2)
clip = core.std.StackHorizontal([r, l])
t = core.std.Crop(clip, top=clip.height / 2)
b = core.std.Crop(clip, bottom=clip.height / 2)
return core.std.StackVertical([t, b])
这个脚本将使阈值以下的数值(即黑色边界)显示为大部分黑色背景上中间的垂直或水平白线。如果没有给出阈值,它将简单地将剪辑的边缘居中。你可以在激活这个功能的情况下浏览一下你的视频。一个自动的替代方法是dirtdtct,它将为你扫描视频。
其他种类的可变脏线是一个婊子修复,需要手动检查场景。
可变的边界
一个与脏线非常相似的问题是不需要的边框。在不同裁剪的场景中(如IMAX或4:3),黑色边框有时可能不完全是黑色的,或者完全被打乱了。为了解决这个问题,只需将其裁剪并重新添加。你也可能想修复沿途可能出现的脏线:
crop = core.std.Crop(src, left=100, right=100)
clean = core.cf.ContinuityFixer(crop, left=2, right=2, top=0, bottom=0, radius=25)
out = core.std.AddBorders(clean, left=100, right=100)
如果你要调整大小,你应该在调整大小之前把这些裁剪掉,然后再把边框加回来,因为在调整大小的过程中留下黑条会产生脏线:
crop = src.std.Crop(left=100, right=100)
clean = crop.cf.ContinuityFixer(left=2, right=2, top=2, radius=25)
resize = awf.zresize(clean, preset=720)
border_size = (1280 - resize.width) / 2
bsize_mod2 = border_size % 2
out = resize.std.AddBorders(left=border_size - bsize_mod2, right=border_size + bsize_mod2)
在上面的例子中,我们必须在一边比另一边多加一些,以达到我们想要的宽度。 理想情况下,你的border_size是mod2,你就不必这样做了。
如果你知道你有这样的边界,你可以使用awsmfunc中的brdrdtct,类似于dirtdtct来扫描文件中的边界。
0.88伽马bug
如果你有两个源,其中一个明显比另一个亮,那么稍微亮的源很有可能受到所谓的伽马bug的影响。 如果是这种情况,请执行以下操作(针对16位),看看是否能解决这个问题:
out = core.std.Levels(src, gamma=0.88, min_in=4096, max_in=60160, min_out=4096, max_out=60160, planes=0)

不要在低位深下执行这一操作。较低的位深可能会导致色带。
For the lazy, the fixlvls wrapper in awsmfunc defaults to a gamma bug fix in 32-bit.
深入解释
这个错误似乎源于苹果软件。 这篇文章是人们可以在网上找到的鲜有提及伽马BUG的文章之一。其原因可能是软件不必要地试图在NTSC伽马(2.2)和PC伽马(2.5)之间进行转换,因为 \(\frac{2.2}{2.5}=0.88\)。
为了解决这个问题,每个值都必须提高到0.88的幂,尽管必须进行电视范围标准化:
\[ v_\mathrm{new} = \left( \frac{v - min_\mathrm{in}}{max_\mathrm{in} - min_\mathrm{in}} \right) ^ {0.88} \times (max_\mathrm{out} - min_\mathrm{out}) + min_\mathrm{out} \]
对于那些好奇有伽马BUG的源和正常源会有什么不同的人来说:除了16、232、233、234和235以外的所有数值都是不同的,最大和最常见的差异是10,从63持续到125。 由于可以输出同等数量的数值,而且该操作通常是在高比特深度下进行的,因此不太可能有明显的细节损失。 然而,请注意,无论比特深度如何,这都是一个有损失的过程。
双倍范围压缩 Double range compression
一个类似的问题是双倍范围压缩。 当这种情况发生时,luma值将在30和218之间。 这可以通过以下方法轻松解决。
out = src.resize.Point(range_in=0, range=1, dither_type="error_diffusion")
out = out.std.SetFrameProp(prop="_ColorRange", intval=1)

深入解释
This issue means something or someone during the encoding pipeline assumed the input to be full range despite it already being in limited range. As the end result usually has to be limited range, this perceived issue is "fixed".One can also do the exact same in std.Levels actually. The following math is applied for changing range:
\[ v_\mathrm{new} = \left( \frac{v - min_\mathrm{in}}{max_\mathrm{in} - min_\mathrm{in}} \right) \times (max_\mathrm{out} - min_\mathrm{out}) + min_\mathrm{out} \]
For range compression, the following values are used: \[ min_\mathrm{in} = 0 \qquad max_\mathrm{in} = 255 \qquad min_\mathrm{out} = 16 \qquad max_\mathrm{out} = 235 \]
As the zlib resizers use 32-bit precision to perform this internally, it's easiest to just use those. However, these will change the file's _ColorRange property, hence the need for std.SetFrameProp.
其他不正确的层级 Other incorrect levels
一个密切相关的问题是其他不正确的层级。要解决这个问题,最好是使用一个具有正确层级的参考源,找到与16和235相当的值,然后从那里进行调整(如果是8位,保险起见,在更高的比特深度中做)。
out = src.std.Levels(min_in=x, min_out=16, max_in=y, max_out=235)
然而,这通常是不可能修复的。相反,我们可以做以下数学运算来计算出正确的调整值:
\[ v = \frac{v_\mathrm{new} - min_\mathrm{out}}{max_\mathrm{out} - min_\mathrm{out}} \times (max_\mathrm{in} - min_\mathrm{in}) + min_\mathrm{in} \]
因此,我们可以从要调整的源中选择任何低值,将其设置为 \(min_\mathrm{in}\),在参考源中选择同一像素的值作为 \(min_\mathrm{out}\)。对于高值和最大值,我们也是这样做的。然后, 我们用16和235来计算 (再次,最好是高位深度--16位的4096和60160,32位浮动的0和1等等。) 这个 \(v_\mathrm{new}\) ,输出值将是上面VapourSynth代码中我们的 \(x\) 和 \(y\)。
为了说明这一点,让我们使用《燃烧》(2018)的德版和美版蓝光片。 美版的蓝光有正确的色调层级,而德版的蓝光有不正确的色调层级。

这里德版的高值是199,而美版的相同像素是207。 对于低值,我们可以找到29和27。 通过这些,我们得到18.6和225.4。 对更多的像素和不同的帧进行这些操作,然后取其平均值,我们得到19和224。 用这些值来调整luma,使我们更接近参考视频的1。

深入解释
看过前面解释的人应该认识到这个函数,因为它是用于色调水平调整的函数的逆向函数。 我们只需把它反过来,把我们的期望值设为 \(v_\mathrm{new}\)并进行计算。不恰当的颜色矩阵 Improper color matrix
如果你有一个不恰当的颜色矩阵的源,你可以用以下方法解决这个问题:
out = core.resize.Point(src, matrix_in_s='470bg', matrix_s='709')
The ’470bg’ is what's also known as 601. To know if you should be
doing this, you'll need some reference sources, preferably not web
sources. Technically, you can identify bad colors and realize that it's
necessary to change the matrix, but one should be extremely certain in such cases.
'470bg'也就是被称为601的东西。要弄清你是否应该这样做,你需要一些参考源,最好不是网络源。从技术上讲,你可以识别坏的颜色,并意识到有必要改变矩阵,但在这种情况下,你必须非常确定。

深入解释
颜色矩阵定义了YCbCr和RGB之间的转换是如何进行的。由于RGB显然没有任何子采样,剪辑首先从4:2:0转换为4:4:4,然后从YCbCr转换为RGB,然后再进行还原。在YCbCr到RGB的转换过程中,我们假设是Rec.601矩阵系数,而在转换回来的过程中,我们指定是Rec.709。之所以很难知道是否假设了不正确的标准,是因为两者涵盖了CIE 1931的类似范围。色度图会使这一点的差异更明显(包括Rec.2020作为参考):

取整错误 Rounding error
一点轻微的绿色色调可能表明发生了取整错误。 这个问题在亚马逊、CrunchyRoll等流媒体的源中特别常见。 为了解决这个问题,我们需要在比源更高的位深上增加半步。
high_depth = vsutil.depth(src, 16)
half_step = high_depth.std.Expr("x 128 +")
out = vsutil.depth(half_step, 8)

另外,也可以使用lvsfunc.misc.fix_cr_tint。
与上面的效果相同
Sometimes, sources will require slightly different values, although these will always be multiples of 16, with the most common after 128 being 64.
It is also not uncommon for differing values to have to be applied to each plane.
This is easily done with std.Expr by using a list of adjustments, where an empty one means no processing is done:
adjust = high_depth.std.Expr(["", "x 64 +", "x 128 +"])
深入解释
当剪辑工作室将他们的10位母盘变成8位时,他们的软件可能总是向下取整(例如1.9会被取整为1)。 我们解决这个问题的方法是简单的增加了一个8位的半步,如(0.5乘以2 ^ {16 - 8} = 128\)检测着色 gettint
gettint脚本可以用来自动检测一个色调是否由一个常见的错误引起。
要使用它,首先裁剪掉任何黑边、文本和任何其他可能不着色的元素。
然后,简单地运行它并等待结果:
$ gettint source.png reference.png
该脚本还可以接受视频文件,它将选择中间的帧,并使用自动裁剪来消除黑条。
如果没有检测到导致色调的常见错误,脚本将尝试通过伽玛、增益和偏移、或层级调整调整来匹配。
这里已经解释了所有这些的修复方法,除了增益和偏移,可以用std.Expr来修复:
gain = 1.1
offset = -1
out = core.std.Expr(f"x {gain} / offset -")
请注意,如果使用gamma bug修复(或fixlvls)中的gamma修复功能,来自gettint的gamma将需要被反转。
除着色 Detinting
请注意,只有在其他方法都失败的情况下,你才应该采用这种方法。
如果你有一个较好的有着色的源,和一个较差的没有着色的来源,而你想把它剔除,
你可以用 timecube 和 DrDre's Color Matching Tool2。
首先,在工具中添加两张参考截图,导出LUT,保存它,并通过类似的方式添加它:
clip = core.resize.Point(src, matrix_in_s="709", format=vs.RGBS)
detint = core.timecube.Cube(clip, "LUT.cube")
out = core.resize.Point(detint, matrix=1, format=vs.YUV420P16, dither_type="error_diffusion")

为了简单起见,这里没有涉及色度平面。 这些需要做的工作远远多于luma平面,因为很难找到非常鲜艳的颜色,尤其是像这样的截图。 2: 令人遗憾的是,这个程序是闭源的。 我不知道有什么替代品。
需要重新格式化
蒙版是一个不那么直接的话题。其原理是根据源图像的属性来限制滤镜的应用。蒙版通常是灰度的,据此,应用多少有关的两个片段是由蒙版的亮度决定的。所以,如果你做
mask = mask_function(src)
filtered = filter_function(src)
merge = core.std.MaskedMerge(src, filtered, mask)
The filtered clip will be used for every completely white pixel in
mask, and the src clip for every black pixel, with in-between values
determining the ratio of which clip is applied. Typically, a mask will
be constructed using one of the following three functions:
-
std.Binarize: This simply separates pixels by whether they are above or below a threshold and sets them to black or white accordingly. -
std.Expr: Known to be a very complicated function. Applies logic via reverse Polish notation. If you don't know what this is, read up on Wikipedia. Some cool things you can do with this are make some pixels brighter while keeping others the same (instead of making them dark as you would withstd.Binarize):std.Expr("x 2000 > x 10 * x ?"). This would multiply every value above 2000 by ten and leave the others be. One nice use case is for in between values:std.Expr("x 10000 > x 15000 < and x {} = x 0 = ?".format(2**src.format.bits_per_sample - 1)).
This makes every value between 10 000 and 15 000 the maximum value allowed by the bit depth and makes the rest zero, just like how astd.Binarizemask would. Many other functions can be performed via this. -
std.Convolution: In essence, apply a matrix to your pixels. The documentation explains it well, so just read that if you don't get it. Lots of masks are defined via convolution kernels. You can use this to do a whole lot of stuff. For example, if you want to average all the values surrounding a pixel, dostd.Convolution([1, 1, 1, 1, 0, 1, 1, 1, 1]). To illustrate, let's say you have a pixel with the value \(\mathbf{1}\) with the following \(3\times3\) neighborhood:\[\begin{bmatrix} 0 & 2 & 4 \\ 6 & \mathbf{1} & 8 \\ 6 & 4 & 2 \end{bmatrix}\]
Now, let's apply a convolution kernel:
\[\begin{bmatrix} 2 & 1 & 3 \\ 1 & 0 & 1 \\ 4 & 1 & 5 \end{bmatrix}\]
This will result in the pixel 1 becoming: \[\frac{1}{18} \times (2 \times 0 + 1 \times 2 + 3 \times 4 + 1 \times 6 + 0 \times \mathbf{1} + 1 \times 8 + 4 \times 6 + 1 \times 4 + 5 \times 2) = \frac{74}{18} \approx 4\]
So, let's say you want to perform what is commonly referred to as a simple "luma mask":
y = core.std.ShufflePlanes(src, 0, vs.GRAY)
mask = core.std.Binarize(y, 5000)
merge = core.std.MaskedMerge(filtered, src, mask)
In this case, I'm assuming we're working in 16-bit. What std.Binarize
is doing here is making every value under 5000 the lowest and every
value above 5000 the maximum value allowed by our bit depth. This means
that every pixel above 5000 will be copied from the source clip.
Let's try this using a filtered clip which has every pixel's value
multiplied by 8:

Simple binarize masks on luma are very straightforward and often do a good job of limiting a filter to the desired area, especially as dark areas are more prone to banding and blocking.
A more sophisticated version of this is adaptive_grain from earlier in
this guide. It scales values from black to white based on both the
pixel's luma value compared to the image's average luma value. A more
in-depth explanation can be found on the creator's blog. We
manipulate this mask using a luma_scaling parameter. Let's use a very
high value of 500 here:

Alternatively, we can use an std.Expr to merge the clips via the
following logic:
if abs(src - filtered) <= 1000:
return filtered
elif abs(src - filtered) >= 30000:
return src
else:
return src + (src - filtered) * (30000 - abs(src - filtered)) / 29000
This is almost the exact algorithm used in mvsfunc.LimitFilter, which
GradFun3 uses to apply its bilateral filter. In VapourSynth, this
would be:
expr = core.std.Expr([src, filtered], "x y - abs 1000 > x y - abs 30000 > x x y - 30000 x y - abs - * 29000 / + x ? y ?")

Now, let's move on to the third option: convolutions, or more interestingly for us, edge masks. Let's say you have a filter that smudges details in your clip, but you still want to apply it to detail-free areas. We can use the following convolutions to locate horizontal and vertical edges in the image:
\[\begin{aligned} &\begin{bmatrix} 1 & 0 & -1 \\ 2 & 0 & -2 \\ 1 & 0 & -1 \end{bmatrix} &\begin{bmatrix} 1 & 2 & 1 \\ 0 & 0 & 0 \\ -1 & -2 & -1 \end{bmatrix}\end{aligned}\]
Combining these two is what is commonly referred to as a Sobel-type edge mask. It produces the following for our image of the lion:
 Now, this result is obviously rather boring. One can see a rough outline
of the background and the top of the lion, but not much more can be made
out.
Now, this result is obviously rather boring. One can see a rough outline
of the background and the top of the lion, but not much more can be made
out.
To change this, let's introduce some new functions:
-
std.Maximum/Minimum: Use this to grow or shrink your mask, you may additionally want to applycoordinates=[0, 1, 2, 3, 4, 5, 6, 7]with whatever numbers work for you in order to specify weights of the surrounding pixels. -
std.Inflate/Deflate: Similar to the previous functions, but instead of applying the maximum of pixels, it merges them, which gets you a slight blur of edges. Useful at the end of most masks so you get a slight transition between masked areas.
We can combine these with the std.Binarize function from before to get
a nifty output:
mask = y.std.Sobel()
binarize = mask.std.Binarize(3000)
maximum = binarize.std.Maximum().std.Maximum()
inflate = maximum.std.Inflate().std.Inflate().std.Inflate()
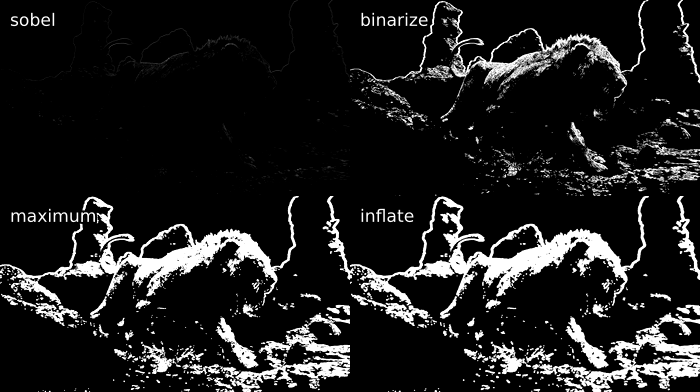
A common example of a filter that might smudge the output is an anti-aliasing or a debanding filter. In the case of an anti-aliasing filter, we apply the filter via the mask to the source, while in the case of the debander, we apply the source via the mask to the filtered source:
mask = y.std.Sobel()
aa = taa.TAAmbk(src, aatype=3, mtype=0)
merge = core.std.MaskedMerge(src, aa, mask)
deband = src.f3kdb.Deband()
merge = core.std.MaskedMerge(deband, src, mask)
We can also use a different edge mask, namely kgf.retinex_edgemask,
which raises contrast in dark areas and creates a second edge mask using
the output of that, then merges it with the edge mask produced using the
untouched image:

This already looks great. Let's manipulate it similarly to before and see how it affects a destructive deband in the twig area at the bottom:
deband = src.f3kdb.Deband(y=150, cb=150, cr=150, grainy=0, grainc=0)
mask = kgf.retinex_edgemask(src).std.Binarize(8000).std.Maximum()
merge = core.std.MaskedMerge(deband, src, mask)

While some details remain smudged, we've successfully recovered a very noticeable portion of the twigs. Another example of a deband suffering from detail loss without an edge mask can be found under figure 35 in the appendix.
Other noteworthy edge masks easily available in VapourSynth include:
-
std.Prewittis similar to Sobel. It's the same operator with the 2 switched out for a 1. -
tcanny.TCannyis basically a Sobel mask thrown over a blurred clip. -
kgf.kirschwill generate almost identical results toretinex_edgemaskin bright scenes, as it's one of its components. Slower than the others, as it uses more directions, but will get you great results.
Some edge mask comparisons can be found in the appendix under figures 26{reference-type="ref" reference="fig:16"}, 30{reference-type="ref" reference="fig:10"} and 34{reference-type="ref" reference="fig:23"}.
As a debanding alternative to edge masks, we can also use "range"
masks, which employ std.Minimum and std.Maximum to locate details.
The most well known example of this is the mask inside GradFun3. This
works as follows:
Then, two clips are created, one which will employ std.Maximum, while
the other obviously will use std.Minimum. These use special
coordinates depending on the mrad value given. If
\(\mathtt{mrad} \mod 3 = 1\), [0, 1, 0, 1, 1, 0, 1, 0] will be used as
coordinates. Otherwise, [1, 1, 1, 1, 1, 1, 1, 1] is used. Then, this
process is repeated with \(\mathtt{mrad} = \mathtt{mrad} - 1\) until
$\mathtt{mrad} = 0$. This all probably sounds a bit overwhelming, but
it's really just finding the maximum and minimum values for each pixel
neighborhood.
Once these are calculated, the minimized mask is subtracted from the
maximized mask, and the mask is complete. So, let's look at the output
compared to the modified retinex_edgemask from earlier:

Here, we get some more pixels picked up by the GradFun3 mask in the
skies and some brighter flat textures. However, the retinex-type edge
mask prevails in darker, more detailed areas. Computationally, our
detail mask is a lot quicker, however, and it does pick up a lot of what
we want, so it's not a bad choice.
Fortunately for us, this isn't the end of these kinds of masks. There
are two notable masks based on this concept: debandmask and
lvsfunc.denoise.detail_mask. The former takes our GradFun3 mask and
binarizes it according to the input luma's brightness. Four parameters
play a role in this process: lo, hi, lothr, and hithr. Values
below lo are binarized according to lothr, values above hi are
binarized according to hithr, and values in between are binarized
according to a linear scaling between the two thresholds:
\[\frac{\mathtt{mask} - \mathtt{lo}}{\mathtt{hi} - \mathtt{lo}} \times (\mathtt{hithr} - \mathtt{lothr}) + \mathtt{lothr}\]
This makes it more useful in our specific scenario, as the mask becomes
stronger in darks compared to GradFun3. When playing around with the
parameters, we can e.. lower lo so we our very dark areas aren't
affected too badly, lower lothr to make it stronger in these darks,
raise hi to enlarge our lo to hi gap, and raise hithr to weaken
it in brights. Simple values might be
lo=22 << 8, lothr=250, hi=48 << 8, hithr=500:

While not perfect, as this is a tough scene, and parameters might not be optimal, the difference in darks is obvious, and less banding is picked up in the background's banding.
Our other option for an altered GradFun3 is lvf.denoise.detail_mask.
This mask combines the previous idea of the GradFun3 mask with a
Prewitt-type edge mask.
First, two denoised clips are created using KNLMeansCL, one with half
the other's denoise strength. The stronger one has a GradFun3-type
mask applied, which is then binarized, while the latter has a Prewitt
edge mask applied, which again is binarized. The two are then combined
so the former mask gets any edges it may have missed from the latter
mask.
The output is then put through two calls of RemoveGrain, the first one
setting each pixel to the nearest value of its four surrounding pixel
pairs' (e.. top and bottom surrounding pixels make up one pair) highest
and lowest average value. The second call effectively performs the
following convolution:
\[\begin{bmatrix}
1 & 2 & 1 \\
2 & 4 & 2 \\
1 & 2 & 1
\end{bmatrix}\]
By default, the denoiser is turned off, but this is one of its
advantages for us in this case, as we'd like the sky to have fewer
pixels picked up while we'd prefer more of the rest of the image to be
picked up. To compare, I've used a binarize threshold similar to the one
used in the debandmask example. Keep in mind this is a newer mask, so
my inexperience with it might show to those who have played around with
it more:

Although an improvement in some areas, in this case, we aren't quite getting the step up we would like. Again, better optimized parameters might have helped.
In case someone wants to play around with the image used here, it's available in this guide's repository: https://git.concertos.live/Encode_Guide/mdbook-guide/src/branch/master/src/filtering/Pictures/lion.png.
{kind=link}
Additionally, the following functions can be of help when masking, limiting et cetera:
-
std.MakeDiffandstd.MergeDiff: These should be self-explanatory. Use cases can be applying something to a degrained clip and then merging the clip back, as was elaborated in the Denoising section. -
std.Transpose: Transpose (i.. flip) your clip. -
std.Turn180: Turns by 180 degrees. -
std.BlankClip: Just a frame of a solid color. You can use this to replace bad backgrounds or for cases where you've added grain to an entire movie but you don't want the end credits to be full of grain. To maintain TV range, you can usestd.BlankClip(src, color=[16, 128, 128]) for 8-bit black. Also useful for making area based masks. -
std.Invert: Self-explanatory. You can also just swap which clip gets merged via the mask instead of doing this. -
std.Limiter: You can use this to limit pixels to certain values. Useful for maintaining TV range (std.Limiter(min=16, max=235)). -
std.Median: This replaces each pixel with the median value in its neighborhood. Mostly useless. -
std.StackHorizontal/std.StackVertical: Stack clips on top of/next to each other. -
std.Merge: This lets you merge two clips with given weights. A weight of 0 will return the first clip, while 1 will return the second. The first thing you give it is a list of clips, and the second item is a list of weights for each plane. Here's how to merge chroma from the second clip into luma from the first:std.Merge([first, second], [0, 1]). If no third value is given, the second one is copied for the third plane. -
std.ShufflePlanes: Extract or merge planes from a clip. For example, you can get the luma plane withstd.ShufflePlanes(src, 0, vs.GRAY).
If you want to apply something to only a certain area, you can use the
wrapper rekt or rekt_fast. The latter only applies you function
to the given area, which speeds it up and is quite useful for
anti-aliasing and similar slow filters. Some wrappers around this exist
already, like rektaa for anti-aliasing. Functions in rekt_fast are
applied via a lambda function, so instead of src.f3kdb.Deband(), you
input rekt_fast(src, lambda x: x.f3kdb.Deband()).
One more very special function is std.FrameEval. What this allows you
to do is evaluate every frame of a clip and apply a frame-specific
function. This is quite confusing, but there are some nice examples in
VapourSynth's documentation:
http://www.vapoursynth.com/doc/functions/frameeval.html. Now, unless
you're interested in writing a function that requires this, you likely
won't ever use it. However, many functions use it, including
kgf.adaptive_grain, awf.FrameInfo, fvf.AutoDeblock, TAAmbk, and
many more. One example I can think of to showcase this is applying a
different debander depending on frame type:
import functools
def FrameTypeDeband(n, f, clip):
if clip.props['_PictType'].decode() == "B":
return core.f3kdb.Deband(clip, y=64, cr=0, cb=0, grainy=64, grainc=0, keep_tv_range=True, dynamic_grain=False)
elif clip.props['_PictType'].decode() == "P":
return core.f3kdb.Deband(clip, y=48, cr=0, cb=0, grainy=64, grainc=0, keep_tv_range=True, dynamic_grain=False)
else:
return core.f3kdb.Deband(clip, y=32, cr=0, cb=0, grainy=64, grainc=0, keep_tv_range=True, dynamic_grain=False)
out = core.std.FrameEval(src, functools.partial(FrameTypeDeband, clip=src), src)
If you'd like to learn more, I'd suggest reading through the Irrational Encoding Wizardry GitHub group's guide: https://guide.encode.moe/encoding/masking-limiting-etc.html and reading through most of your favorite Python functions for VapourSynth. Pretty much all of the good ones should use some mask or have developed their own mask for their specific use case.
Edge detection is also very thoroughly explained in a lot of digital image processing textbooks, e.g. Digital Image Processing by Gonzalez and Woods.
HQDeringmod
Sharpening
DeHalo_alpha
old function explanation
`DeHalo_alpha` works by downscaling the source according to `rx` and `ry` with a mitchell bicubic ($b=\nicefrac{1}{3},\ c=\nicefrac{1}{3}$) kernel, scaling back to source resolution with blurred bicubic, and checking the difference between a minimum and maximum (check [3.2.14](#masking){reference-type="ref" reference="masking"} if you don't know what this means) for both the source and resized clip. The result is then evaluated to a mask according to the following expressions, where $y$ is the maximum and minimum call that works on the source, $x$ is the resized source with maximum and minimum, and everything is scaled to 8-bit: $$\texttt{mask} = \frac{y - x}{y + 0.0001} \times \left[255 - \texttt{lowsens} \times \left(\frac{y + 256}{512} + \frac{\texttt{highsens}}{100}\right)\right]$$ This mask is used to merge the source back into the resized source. Now, the smaller value of each pixel is taken for a lanczos resize to $(\texttt{height} \times \texttt{ss})\times(\texttt{width} \times \texttt{ss})$ of the source and a maximum of the merged clip resized to the same resolution with a mitchell kernel. The result of this is evaluated along with the minimum of the merged clip resized to the aforementioned resolution with a mitchell kernel to find the minimum of each pixel in these two clips. This is then resized to the original resolution via a lanczos resize, and the result is merged into the source via the following:if original < processed
x - (x - y) * darkstr
else
x - (x - y) * brightstr
Masking
Denoising
BM3D
KNLMeansCL
SMDegrain
Grain Dampening
STPresso
Dehardsubbing
hardsubmask
hardsubmask_fades
Delogoing
DeLogoHD
首先,您需要选择视频文件的一个较小区域作为参考,因为对整个内容进行测试将花费很长时间。
推荐的方法是使用 awsmfunc里的SelectRangeEvery:
import awsmfunc as awf
out = awf.SelectRangeEvery(clip, every=15000, length=250, offset=[1000, 5000])
这里,第一个数字是节之间的偏移量,第二个数字是每个节的长度,偏移数组是从开始到结束的偏移量。
您需要使用相当长的剪辑(通常为几千帧),其中包括黑暗、明亮、静态和动作场景, 但是,它们的分布应该与它们在整个视频中的分布大致相同。
在测试设置时,您应该始终使用 2-pass 编码,因为许多设置会显着改变 CRF 为您提供的比特率。 对于最终编码,两者都很好,尽管 CRF 更快。
要找出最佳设置,请将它们相互对比并与源进行比较。 你可以单独这样做,或者在`awsmfunc'文件夹中交错排列一个文件夹。你通常也想给它们贴上标签,这样你就可以让你真正知道你在看哪个片段。
# Load the files before this
src = awf.FrameInfo(src, "Source")
test1 = awf.FrameInfo(test1, "Test 1")
test2 = awf.FrameInfo(test2, "Test 2")
out = core.std.Interleave([src, test1, test2])
# You can also place them all in the same folder and do
src = awf.FrameInfo(src, "Source")
folder = "/path/to/settings_folder"
out = awf.InterleaveDir(src, folder, PrintInfo=True, first=extract, repeat=True)
如果你使用yuuno,你可以使用下面的iPython魔法来获得 悬停在预览屏幕上,使预览在两个源之间切换
屏幕。
%vspreview --diff
clip_A = core.ffms2.Source("settings/crf/17.0")
clip_A.set_output()
clip_B = core.ffms2.Source("settings/crf/17.5")
clip_B.set_output(1)
通常情况下,你会想先测试一下比特率。只要在几个不同的CRF下进行编码,并与源文件进行比较,找到与源文件无法区分的最高CRF值。 现在,对数值进行四舍五入,最好是向下,并切换到2-pass。对于标准测试,测试qcomp(间隔为0.05),有大跨度 aq-strengths 的 aq-modes(例如,对于一个aq-mode做测试,aq-strengths 从0.6到1.0,间隔为0.2),aq-strengths(间隔为0.05),merange(32,48和64),psy-rd(间隔为0.05),ipratio/bratio(间隔为0.05,距离保持为0.10),然后deblock(间隔为1)。 如果你认为 mbtree 有所帮助(即你正在进行动画压制),请在打开 mbtree 的情况下重做这个过程。您可能不想对顺序进行太多更改,但当然可以这样做。
对于x265,顺序应该是qcomp、aq-mode、aq-strength、psy-rd、psy-rdoq、ipratio和pbratio,然后是deblock。
如果你想要一点额外的效率,你可以在你最终决定的每个设置的数值周围用较小的间隔再次进行测试。建议在你已经对每个设置做了一次测试之后再做,因为它们确实对彼此都有轻微的影响。
一旦你完成了用2-pass的测试设置,就切换回CRF,并重复寻找最高透明CRF值的过程。
General settings
These are the settings that you shouldn't touch between encodes.
Preset
Presets apply a number of parameters, which can be referenced here Just use the placebo preset, we'll change the really slow stuff, anyway:
--preset placebo
Level
Where --preset applies a defined set of parameters, --level provides a set of limitations to ensure decoder compatibility. For further reading, see this wikipedia article
For general hardware support level 4.1 is recommended, otherwise you may omit this.
--level 41
Motion estimation
For further reading see this excellent thread on Doom9
x264 has two motion estimation algorithms worth using, umh and tesa. The latter is a placebo option that's really, really slow, and seldom yields better results, so only use it if you don't care about encode time. Otherwise, just default to umh:
--me umh
Ratecontrol lookahead
The ratecontrol lookahead (rc-lookahead) setting determines how far ahead the video buffer verifier (VBV) and macroblock tree (mbtree) can look. Raising this can slightly increase memory use, but it's generally best to leave this as high as possible:
--rc-lookahead 250
If you're low on memory, you can lower it to e.g. 60.
Source-specific settings
These settings should be tested and/or adjusted for every encode.
Profile
Just set this according to the format you're encoding:
--profile high
highfor 8-bit 4:2:0high444for 10-bit 4:4:4, 4:2:2, 4:2:0, lossless
Ratecontrol
Beyond all else, this is the single most important factor for determining the quality from any given input. Due to how poorly x264 handles lower bitrates (comparatively, particularly when encoding 8-bit) starving your encode will result in immediate artifacts observable even under the lightest scrutiny.
While manipulating other settings may make small, but usually noticeable differences; an encode can't look great unless given enough bits.
For some futher insight, reference this article
Constant ratefactor
For more information please see this post by an x264 developer.
The constant ratefactor (CRF) is the suggested mode for encoding. Rather than specifying a target bitrate, CRF attempts to ensure a consistent quality across a number of frames; as such, the resulting bitrate will only be consistent if passed identical values. In short, CRF is recommended for use with your finalized encode, not testing, where two pass is recommended.
Lower CRF values are higher quality, higher values lower. Some settings will have a very large effect on the bitrate at a constant CRF, so it's hard to recommend a CRF range, but most encodes will use a value between 15.0 and 20.0. It's best to test your CRF first to find an ideal bitrate, then test it again after all other settings have been tested with 2pass.
To specify CRF:
--crf 16.9
Two pass
An alternative to CRF which leverages an initial pass to collect information about the input before encoding. This comes with two distinct advantages:
- The ability to target a specific bitrate
- Effectively infinite lookahead
This is very suitable for testing settings, as you will always end up at almost the same bitrate no matter what.
As mentioned previously, to encode this two runs are necessary. The first pass can be sent to /dev/null, since all we care about is the stats file.
To specify which of the two passes you're encoding all we need to change is --pass
vspipe -c y4m script.vpy - | x264 --demuxer y4m --preset placebo --pass 1 --bitrate 8500 -o /dev/null -
vspipe -c y4m script.vpy - | x264 --demuxer y4m --preset placebo --pass 2 --bitrate 8500 -o out.h264 -
Deblock
For an explanation of what deblock does, read this Doom9 post and this blog post
Set this too high and you'll have a blurry encode, set it too low and you'll have an overly blocky encode.
We recommend testing deblock in a range of -2:-2 to 0:0 (animated content should use stronger deblock settings).
Usually, you can test this with the same alpha and beta parameters at first, then test offsets of \(\pm1\).
Many people will mindlessly use -3:-3, but this tends to lead to unnecessary blocking that could've been avoided had this setting been tested.
To specify e.g. an alpha of -2 and a beta of -1:
--deblock -2:-1
Quantizer curve compression
The quantizer curve compression (qcomp) is effectively the setting that determines how bits are distributed among the whole encode. It has a range of 0 to 1, where 0 is a constant bitrate and 1 is a constant quantizer, the opposite of a constant bitrate. This means qcomp affects how much bitrate you're giving to "important" scenes as opposed to "unimportant" scenes. In other words, it can be seen as the trade-off between bitrate allocation to simple or static scenes and complex or high motion scenes. Higher qcomp will allocate more to the latter, lower to the former.
It's usually recommended to set this between 0.60 and 0.70 without mbtree and 0.70 and 0.85 with mbtree.
You want to find that sweet spot where complex scenes will look good enough without ruining simple scenes.
--qcomp 0.60
Macroblock tree
From this thread by an x264 developer: "It tracks the propagation of information from future blocks to past blocks across motion vectors. It could be described as localizing qcomp to act on individual blocks instead of whole scenes. Thus instead of lowering quality in high-complexity scenes (like x264 currently does), it'll only lower quality on the complex part of the scene, while for example a static background will remain high-quality. It also has many other more subtle effects, some potentially negative, most probably not."
Curious readers can reference the paper directly
Macroblock tree ratecontrol (mbtree) can lead to large savings for very flat content, but tends to be destructive on anything with a decent amount of grain. If you're encoding something flat, like a cartoon or modern anime, it's recommended to test this setting to see if it's worth it.
When using mbtree, you should max out your lookahead (--rc-lookahead 250) and use a high qcomp (\(\geq 0.70\)).
Adaptive quantization
While qcomp determines bit allocation for frames across the video, adaptive quantization (AQ) is in charge of doing this on a block-basis, distributing bits not only within the current frame, but also adjacent frames. [citation needed] It does so by distributing bits e.g. from complex to flat blocks.
There are three modes available in vanilla x264:
- Allow AQ to redistribute bits across the whole video and within frames.
- Auto-variance; this attempts to adapt strength per-frame.
- Auto-variance with a bias to dark scenes.
Generally speaking, you'll likely get the best results with AQ mode 3. With the other two modes, you have to carefully make sure that darks aren't being damaged too much. If you e.g. have a source without any dark scenes (or only very few), it can be worth manually allocating more bits to darks via zoning and using AQ modes 1 or 2.
This comes along with a strength parameter. For modes 1 and 2, you usually want a strength between 0.80 and 1.30. Mode 3 is a bit more aggressive and usually looks best with a strength between 0.60 and 0.85.
Raising the AQ strength will help flatter areas, e.g. by maintaining smaller grain and dither to alleviate banding. However, higher AQ strengths will tend to distort edges more.
Older, grainier live action content will usually benefit more from lower AQ strengths and may benefit less from the dark scene bias present in AQ mode 3, while newer live action tends to benefit more from higher values. For animation, this setting can be very tricky; as both banding and distorted edges are more noticeable. It's usually recommended to run a slightly lower AQ strength, e.g. around 0.60 to 0.70 with mode 3.
To use e.g. AQ mode 3 with strength 0.80:
--aq-mode 3 --aq-strength 0.80
Motion estimation range
The motion estimation range (merange) determines how many pixels are used for motion estimation.
Larger numbers will be slower, but can be more accurate for higher resolutions.
However, go too high, and the encoder will start picking up unwanted info, which in turn will harm coding efficiency.
You can usually get by with testing 32, 48, and 64, then using the best looking one, preferring lower numbers if equivalent:
--merange 32
Frametype quantizer ratio
These settings determine how bits are distributed among the different frame types.
Generally speaking, you want to have an I-frame to P-frame ratio (ipratio) around 0.10 higher than your P-frame to B-frame ratio (pbratio).
Usually, you'll want to lower these from the defaults of 1.40 for ipratio and 1.30 for pbratio, although not by more than 20.
Lower ratios will tend to help with grainier content, where less information from previous frames can be used, while higher ratios will usually lead to better results with flatter content.
You can use the stats created by the x264 log at the end of the encoding process to check whether the encoder is overallocating bits to a certain frametype and investigate whether this is a problem. A good guideline is for P-frames to be double the size of B-frames and I-frames in turn be double the size of P-frames. However, don't just blindly set your ratios so that this is the case. Always use your eyes.
To set an ipratio of 1.30 and a pbratio of 1.20:
--ipratio 1.30 --pbratio 1.20
If using mbtree, pbratio doesn't do anything, so only test and set ipratio.
Psychovisually optimized rate-distortion optimization
One big issue with immature encoders is that they don't offer psychovisual optimizations like psy-rdo. What it does is distort the frame slightly, sharpening it in the process. This will make it statistically less similar to the original frame, but will look better and more similar to the input. What this means is this is a weak sharpener of sorts, but a very much necessary sharpener!
The setting in x264 comes with two options, psy-rdo and psy-trellis, which are both set via the same option:
--psy-rd rdo:trellis
Unfortunately, the latter will usually do more harm than good, so it's best left off.
The psy-rdo strength should be higher for sharper content and lower for blurrier content. For animated content, psy-rdo can introduce ringing even with default values. We suggest using lower values, between 0.60 and 0.90. For live action content where this is of much lesser concern you should find success with values around 0.95 to 1.10.
When testing this, pay attention to whether content looks sharp enough or too sharp, as well as whether anything gets distorted during the sharpening process.
For example, to set a psy-rd of 1.00 and psy-trellis of 0:
--psy-rd 1.00:0
DCT block decimation
Disabling DCT block decimation (no-dct-decimate) is very common practice, as it drops blocks deemed unimportant. For high quality encoding, this is often unwanted and disabling this is wise. However, for flatter content, leaving this on can aid with compression. Just quickly test on and off if you're encoding something flat.
To disable DCT block decimation:
--no-dct-decimate
Video buffer verifier
To understand what this is, there's actually a Wikipedia article you can read. Alternatively, you may find this video presentation from demuxed informative.
For us, the main relevance is that we want to disable this when testing settings, as video encoded with VBV enabled will be non-deterministic. Otherwise, just leave it at your level's defaults.
To disable VBV:
--vbv-bufsize 0 --vbv-maxrate 0
VBV settings for general hardware compliance (High@L4.1)
--vbv-bufsize 78125 --vbv-maxrate 62500
Reference frames
The reference frames (ref) setting determines how many frames P frames can use as reference. Many existing guides may provide an incorrect formula to find the 'correct' value. Do not use this. Rather, allow x264 to calculate this for automatically (as dictated by --level).
Otherwise, if you don't care about compatibility with 15 year old TVs and 30 year old receivers, set this however high you can bare, with a maximum value of 16. Higher refs will improve encoder efficiency at the cost of increased compute time.
To set the maximum value of 16:
--ref 16
Zones
Sometimes, the encoder might have trouble distributing enough bits to certain frames, e.g. ones with wildly different visuals or sensitive to banding. To help with this, one can zone out these scenes and change the settings used to encode them.
When using this to adjust bitrate, one can specify a CRF for the zone or a bitrate multiplier.
It's very important to not bloat these zones, e.g. by trying to maintain all the grain added while debanding.
Sane values tend to be \(\pm 2\) from base CRF or bitrate multipliers between 0.75 and 1.5.
To specify a CRF of 15 for frames 100 through 200 and 16 for frames 300 through 400, as well as a bitrate multiplier of 1.5 for frames 500 through 600:
--zones 100,200,crf=15/300,400,crf=16/500,600,b=1.5
For a more complete picture of what --zones can and can not manipulate, see this section.
Output depth and color space
To encode 10-bit and/or 4:4:4 video, one must specify this via the following parameters:
--output-depth 10 --output-csp i444
The official documentation for x265 is very good, so this page will only cover recommended values and switches.
Source-independent settings
-
--preset verysloworslower -
--no-rectfor slower computers. There's a slight chance it'll prove useful, but it probably isn't worth it. -
--no-ampis similar torect, although it seems to be slightly more useful. -
--no-open-gop -
--no-cutreesince this seems to be a poor implementation ofmbtree. -
--no-rskiprskipis a speed up that gives up some quality, so it's worth considering with bad CPUs. -
--ctu 64 -
--min-cu-size 8 -
--rdoq-level 2 -
--max-merge 5 -
--rc-lookahead 60although it's irrelevant as long as it's larger than min-keyint -
--ref 6for good CPUs, something like4for worse ones. -
--bframes 16or whatever your final bframes log output says. -
--rd 3or4(they're currently the same). If you can endure the slowdown, you can use6, too, which allows you to test--rd-refine. -
--subme 5. You can also change this to7, but this is known to sharpen. -
--merange 57just don't go below32and you should be fine. -
--high-tier -
--range limited -
--aud -
--repeat-headers
Source-dependent settings
-
--output-depth 10for 10-bit output. -
--input-depth 10for 10-bit input. -
--colorprim 9for HDR,1for SDR. -
--colormatrix 9for HDR,1for SDR. -
--transfer 16for HDR,1for SDR. -
--hdr10for HDR. -
--hdr10-optfor 4:2:0 HDR,--no-hdr10-optfor 4:4:4 HDR and SDR. -
--dhdr10-info /path/to/metadata.jsonfor HDR10+ content with metadata extracted using hdr10plus_parser.
-
--dolby-vision-profile 8.1specified Dolby Vision profile. x265 can encode only to profiles5,8.1, and8.2 -
--dolby-vision-rpu /path/to/rpu.binfor Dolby Vision metadata extracted using dovi_tool. -
--master-display "G(8500,39850)B(6550,2300)R(35400,14600)WP(15635,16450)L(10000000,20)"for BT.2020 or
G(13250,34500)B(7500,3000)R(34000,16000)WP(15635,16450)L(10000000,1)for Display P3 mastering display color primaries with the values for L coming from your source's MediaInfo for mastering display luminance.For example, if your source MediaInfo reads:
Mastering display color primaries : BT.2020 Mastering display luminance : min: 0.0000 cd/m2, max: 1000 cd/m2 Maximum Content Light Level : 711 cd/m2 Maximum Frame-Average Light Level : 617 cd/m2This means you set
"G(8500,39850)B(6550,2300)R(35400,14600)WP(15635,16450)L(10000000,0)" -
--max-cll "711,617"from your source's MediaInfo for maximum content light level and maximum frame-average light level. The values here are from the above example. -
--cbqpoffsand--crqpoffsshould usually be between -3 and 0 for 4:2:0. For 4:4:4, set this to something between 3 and 6. This sets an offset between the bitrate applied to the luma and the chroma planes. -
--qcompbetween0.60and0.80. -
--aq-mode 4,3,2,1, or--hevc-aqwith4and3usually being the two best options. If using aMod, there is an extra mode5. These do the following:-
Standard adaptive quantization, simply add more bits to complex blocks.
-
Adaptive quantization with auto-variance.
-
Adaptive quantization with auto-variance and bias to dark scenes.
-
Adaptive quantization with auto-variance and better edge preservation.
-
Adaptive quantization with auto-variance, better edge preservation, and bias to dark scenes. Only in aMod.
-
hevc-aq"scales the quantization step size according to the spatial activity of one coding unit relative to frame average spatial activity. This AQ method utilizes the minimum variance of sub-unit in each coding unit to represent the coding unit's spatial complexity." Like most of the x265 documentation, this sounds a lot fancier than it is. Don't enable with other modes turned on.
-
-
--aq-strengthbetween0.80and1.40for AQ modes 1-3 or0.50and1.00for AQ mode 4. -
--aq-bias-strengthbetween0.50and1.20if using aMod and an AQ mode with dark bias. This is a multiplier with lower numbers lowering the bias. Default is1.00. -
--deblock -4:-4to0:0, similar to x264. Test at least -3:-3 to -1:-1 with live action, -2:-2 to 0:0 with animation. -
--ipratioand--pbratiosame as x264 again. -
--psy-rd 0.80to2.00, similar-ish effect to x264. Values are generally higher than with x264, though. -
--psy-rdoqanything from0.00to2.00usually. -
--no-saois usually best, but if your encode suffers from a lot of ringing, turn SAO back on. SAO does tend to blur quite heavily. -
--no-strong-intra-smoothingon sharp/grainy content, you can leave this on for blurry content, as it's an additional blur that'll help prevent banding.
截图 Taking Screenshots
在VapourSynth中拍摄简单的屏幕截图是非常容易的。 如果你使用的是previewer,你可以用它来代替,,但知道如何直接通过VapourSynth进行截图可能还是很有用的。
我们推荐使用 awsmfunc.ScreenGen.
它有两个优势:
- 保存了帧数编号,可以很容易再次引用,例如,如果你想重新做你的截图。
- 为你处理适当的转换和压缩,而有些previewer(例如VSEdit)可能不是这样的。
要使用ScreenGen,首先创建一个你想要截图的新文件夹,例如 "Screenshots",和一个名为 "screen.txt "的文件,其中包含你想要截图的帧数,例如:
26765
76960
82945
92742
127245
然后,在你的VapourSynth脚本最后,写上
awf.ScreenGen(src, "Screenshots", "a")
a是放在帧编号后面的东西。
这对于保持文件结构和对截图进行分类是很有用的,同时也可以防止不必要的截图被覆盖。
现在,在命令行中运行你的脚本(或在previewer中重新加载)。
python vapoursynth_script.vpy
完成! 你的截图现在应该在给定的文件夹中。
对比源与压制 Comparing Source vs. Encode
将source与你的压制作品进行比较,可以让潜在的下载者轻松判断你的压制质量。
在进行比较时,包含的比较帧的类型非常重要,例如比较两个I帧将导致极其有利的结果。
你可以使用awsmfunc.FrameInfo来做这个:
src = awf.FrameInfo(src, "Source")
encode = awf.FrameInfo(encode, "Encode")
如果你想在你的previewer中比较这些,建议将它们交错排列。
out = core.std.Interleave([src, encode])
然而,如果你是用ScreenGen进行截图,将会非常简单,只需调用两次ScreenGen:
src = awf.FrameInfo(src, "Source")
awf.ScreenGen(src, "Screenshots", "a")
encode = awf.FrameInfo(encode, "Encode")
awf.ScreenGen(encode, "Screenshots", "b")
注意,在压制的ScreenGen中,"a"被替换成了"b"。
这将允许你按名字对文件夹进行排序,并且每张源截图后面都有一个压制截图,使上传更容易。
HDR对比 HDR comparisons
对于比较HDR源与HDR压制,建议进行色调映射。 这个过程具有破坏性,但你仍然能够分辨出哪些地方被扭曲了,哪些地方被平滑了等等。
推荐使用awsmfunc.DynamicTonemap方法:
src = awf.DynamicTonemap(src)
encode = awf.DynamicTonemap(encode, reference=src)
第二个色调映射方法中的 reference=src 确保了两个色调映射输出的一致性。
选择帧 Choosing frames
在进行截图时,不要让你的压制看起来有欺骗性的透明是非常重要的。 要做到这一点,你需要确保你截图的是较多适当的帧类型,以及内容上不同的帧。
幸运的是,这里没有太多需要记住的东西:
- 你的压制截图图应该永远是B类型帧。
- 你的源截图不应该是I类型帧。
- 你的比较截图应该包括黑暗场景、明亮场景、特写镜头、远景镜头、静态场景、高度动作场景,以及介于两者之间的任何场景
比较不同的源 Comparing Different Sources
当比较不同的源时,你应该进行类似于比较源与压制的步骤。 然而,你可能会遇到不同的裁剪、分辨率或色调,所有这些都会妨碍比较的进行。
对于不同的裁剪,只需将边框加回去:
src_b = src_b.std.AddBorders(left=X, right=Y, top=Z, bottom=A)
如果这样做会导致图像内容的偏移,你应该调整大小为4:4:4,这样你就可以添加不均匀的边框。 例如,如果你想在顶部和底部添加1像素高的黑条:
src_b = src_b.resize.Spline36(format=vs.YUV444P8, dither_type="error_diffusion")
src_b = src_b.std.AddBorders(top=1, bottom=1)
对于不同的分辨率,推荐使用Spline36方法调整大小1:
src_b = src_b.resize.Spline36(src_a.width, src_a.height, dither_type="error_diffusion")
如果一个源是HDR,另一个是SDR,你可以使用awsmfunc.DynamicTonemap方法:
src_b = awf.DynamicTonemap(src_b)
关于不同的色调,可以参考色调篇。
重要的是要确保你在这里调整到适当的分辨率;如果你为1080p编码进行比较,你显然会以1080p进行比较,而如果你是为了弄清楚哪个来源更好而进行比较,你会想把低分辨率的来源提升到与高分辨率相匹配。
如果你的去带片段与没有带子的部分相比颗粒很小,你应该考虑使用一个单独的函数来添加匹配的颗粒,这样场景就更容易融合在一起。如果有很多颗粒,你可能要考虑adptvgrnMod、adaptive_grain或GrainFactory3;对于不那么明显的颗粒,或者只是对于通常会有很少颗粒的明亮场景,你也可以使用grain.Add。颗粒器的主题将在后面的粒化部分中进一步阐述。
下面是Mirai的一个例子:

Black & White Clips: Working in GRAY
由于YUV格式将luma保存在一个单独的平面内,在处理黑白电影时,我们会变得更加轻松,因为我们可以提取luma平面并只在该平面上工作。
y = src.std.ShufflePlanes(0, vs.GRAY)
vsutil中的get_y函数做了同样的事情。
有了我们的y片段,我们可以执行没有mod2限制的功能。
例如,我们可以进行奇数裁剪:
crop = y.std.Crop(left=1)
此外,由于滤镜只应用在一个平面上,这可以加快我们的脚本速度。
我们也不必担心像f3kdb这样的滤镜会以不需要的方式改变我们的色度平面,例如使它们产生颗粒。
然而,当我们完成我们的剪辑后,我们通常想把剪辑导出为YUV。 这里有两个选项:
1. 使用假色度
使用假的色度是快速和简单的,其优点是在源中任何意外的色度偏移(例如色度颗粒)将被删除。 所有这一切都需要恒定的色度(意味着没有色调变化)和mod2 luma。
最简单的选项是u = v = 128(8位):
out = y.resize.Point(format=vs.YUV420P8)
如果你有一个不均匀的luma,只需用awsmfunc.fb来填充它。
假设你想对左边进行填充:
y = core.std.StackHorizontal([y.std.BlankClip(width=1), y])
y = awf.fb(y, left=1)
out = y.resize.Point(format=vs.YUV420P8)
另外,如果你的源的色度不是中性灰色,可以使用std.BlankClip:
blank = y.std.BlankClip(color=[0, 132, 124])
out = core.std.ShufflePlanes([y, blank], [0, 1, 2], vs.YUV)
2. 使用原始色度(必要时调整大小)
这样做的好处是,如果有实际重要的色度信息(例如轻微的棕褐色色调),这将被保留下来。
只要在你的素材上使用ShufflePlanes就可以了:
out = core.std.ShufflePlanes([y, src], [0, 1, 2], vs.YUV)
然而,如果你已经调整了尺寸或裁剪,这就变得有点困难了。 你可能必须适当地移动或调整色度(见色度重采样章节的解释)。
如果你已经裁剪了,就提取并相应地移位。我们将使用vsutil的split和join来提取和合并平面:
y, u, v = split(src)
crop_left = 1
y = y.std.Crop(left=crop_left)
u = u.resize.Spline36(src_left=crop_left / 2)
v = v.resize.Spline36(src_left=crop_left / 2)
out = join([y, u, v])
如果你已经调整了尺寸,你需要转移和调整色度的大小:
y, u, v = split(src)
w, h = 1280, 720
y = y.resize.Spline36(w, h)
u = u.resize.Spline36(w / 2, h / 2, src_left=.25 - .25 * src.width / w)
v = v.resize.Spline36(w / 2, h / 2, src_left=.25 - .25 * src.width / w)
out = join([y, u, v])
结合裁剪和移位,据此我们垫高裁剪并使用awsmfunc.fb来创建一个假线:
y, u, v = split(src)
w, h = 1280, 720
crop_left, crop_bottom = 1, 1
y = y.std.Crop(left=crop_left, bottom=crop_bottom)
y = y.resize.Spline36(w - 1, h - 1)
y = core.std.StackHorizontal([y.std.BlankClip(width=1), y])
y = awf.fb(left=1)
u = u.resize.Spline36(w / 2, h / 2, src_left=crop_left / 2 + (.25 - .25 * src.width / w), src_height=u.height - crop_bottom / 2)
v = v.resize.Spline36(w / 2, h / 2, src_left=crop_left / 2 + (.25 - .25 * src.width / w), src_height=u.height - crop_bottom / 2)
out = join([y, u, v])
如果你不明白这里到底发生了什么,遇到这样的情况,请向更有经验的人求助。